Here you will find details about how information is managed in Unicode.
Code Points
The basic unit of information in Unicode is known as a code point. A code point is simply a number between zero and 10FFFF16 that represents a single entity. Code points are generally represented as hexadecimal numbers, that is base 16. An entity may be any of the following:
| Entity | Description |
|---|---|
| graphic |
A letter, mark, number, punctuation, symbol or space, e.g. the letter |
| format |
Controls the formatting of text, e.g. soft hyphen ( |
| control |
A control character, e.g. the tab character ( |
| private-use |
Not defined in the Unicode 8.0 standard but used by other non-Unicode scripts, e.g. unused cp 1252 character, 9116. |
| surrogate |
Used to select supplementary planes in UTF-16. Characters in the range D800-DFFF16. |
| non-character |
Permanently reserved for internal use. Characters in the range FFFE-FFFF16 and FDD0-FDEF16. |
| reserved |
All unassigned code points, that is code points that are not one of the above. |
The table below lists some code points along with their representation, label and category:
| Code point (hex) | Representation | Label | Category |
|---|---|---|---|
|
E9 |
é |
Latin small letter e with acute |
graphic (letter - lower case) |
|
600 |
|
Arabic number sign |
format (other) |
|
D6A1 |
횡 |
Hangul syllable hoeng |
graphic (letter - other) |
|
B4 |
´ |
Acute accent |
graphic (symbol - modifier) |
|
F900 |
豈 |
Chinese, Japanese, Korean (cjk) compatibility ideograph |
graphic (letter - other) |
A piece of text is logically just a sequence of code points, where each code point represents a part of the text. For example, the piece of text:
豈 ↔ how?
consists of the following code points:
| Code point (hex) | Representation | Label |
|---|---|---|
|
F900 |
豈 |
Chinese, Japanese, Korean (cjk) compatibility ideograph |
|
20 |
|
Space |
|
2194 |
↔ |
Left right arrow |
|
20 |
|
Space |
|
68 |
h |
Latin small letter h |
|
6F |
o |
Latin small letter o |
|
77 |
w |
Latin small letter w |
|
3F |
? |
Question mark |
The code point sequence defines the text itself. There are a number of different ways that the code point sequence can be saved on a computer. One method, called UTF-32, represents each code point as a 32 bit (4 byte) quantity. Such a scheme uses a large amount of storage space as most text uses the Latin alphabet (ASCII), which can be represented in a single byte.
Another encoding is UTF-8. This allows ASCII characters to be stored as a single byte (code points 00-7F), with multiple bytes used for higher code points. UTF-8 is very efficient space wise where the text consists of mainly ASCII characters, and the World Wide Web has adopted it as the preferred encoding method for Unicode code points. EMu also uses UTF-8 as the encoding method. Below, we show a string encoded in UTF-32 with a space between each code point:
豈 ↔ how?
0000F900 00000020 00002194 00000020 00000068 0000006F 00000077 0000003F
And the same string encoded in UTF-8:
EFA480 20 E28694 20 68 6F 77 3F
As you can see the UTF-8 encoding saves considerable space.
Prior to EMu 5.0 either UTF-8 or ISO-8859-1 could be configured as the encoding method. EMu 5.0 drops support for ISO-8859-1 and only supports UTF-8 encoded characters. The change means that moving to EMu 5.0 requires all data to be converted from ISO-8859-1 to UTF-8 before the system may be used. The upgrade process performs this important function.
Inputting Unicode Characters
Now that we understand that text is made up of a sequence of Unicode code points it is worth considering how these characters can be entered into EMu.
The escaped code point mechanism allows an escape sequence to be placed in a text string to represent a Unicode code point. When the string is sent to the EMu server, the escape sequence is converted into a Unicode code point encoded in UTF-8.
For example, if the text Fr\u{E9}deric was input while creating or modifying a record, the data saved would be Fréderic. The format of the escape sequence is \u{x} where x is the code point in hexadecimal of the Unicode character required. The escape sequence may also be used when entering search terms:
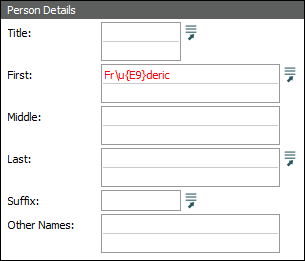
The escape sequence may also be used in texql statements whenever a string constant is required. For example, the query statement:
select NamFirst
from eparties
where NamFirst contains 'Fr\u{E9}deric'
will find all Parties records where the First Name is Fréderic (and variations where diacritics are ignored). The escape sequence format may also be used for data imported into EMu via the Import facility.
The raw character method involves pasting Unicode characters into the required EMu field. There are a number of ways of adding Unicode characters to the Windows clipboard. One way is to use the Windows Character Map application. This can be found on a Window PC by selecting search on the Windows Start menu (or pressing the Windows Logo key and the letter s at the same time) and searching for charmap.
With the Windows Character Map application it is possible to select a character and copy it to the clipboard. By selecting Advance view, it is possible to search for a character by name. For example to find the oe ligature character (œ), enter oe ligature in the Search for: field and press Search. A grid of all matching characters is displayed:

Double-click the required character, then press Copy to place it on the Windows clipboard. The character can then be pasted into EMu.
Another way to add a Unicode character to the Windows clipboard is to use a website that allows Unicode characters to be searched for and displayed. Two useful sites are:
With both of these sites it is possible to search for a character by name or code point (in hex), e.g.:

Highlight the character on the page and copy it to the clipboard. The character can then be pasted into the required EMu field.
Both of these websites display the code point for the character. In the picture above, the code point for œ is hex 153. If you wanted to use the escaped code point method, the escape sequence to use would be:
\u{153}
Tip: If you need to enter certain Unicode characters on a regular basis, you could create a WordPad (or Word) document that contains the characters. When you need a character, simply copy the character from the document and paste it into EMu, without the need to search for the character.
Graphemes
It is important to understand that what we think of as a character, that is a basic unit of writing, may not be represented by a single Unicode code point. Instead, that basic unit may be made up of multiple Unicode code points.
For example, "g" + acute accent (ǵ) is a user-perceived character as we think of it as a single character, however it is represented by two Unicode code points (67 301). A user-perceived character, which consists of one or more code points, is known as a grapheme. The use of graphemes is important for:
- collation (sorting);
- regular expressions;
- indexing; and
- counting character positions within text.
EMu uses graphemes as the basic building block for text. Thus a text string is handled as a sequence of graphemes.
A grapheme consists of one or more base code points followed by zero or more zero width code points and zero or more non-spacing mark code points. In the case of "g" + acute accent (ǵ), the letter g is the base code point (67) and the acute accent is a non-spacing mark code point (301). The table below shows some multiple code point graphemes:
| Grapheme | Code points |
|---|---|
|
각 |
1100 (ᄀ) Hangul choseong kiyeok (base code point) 1161 (ᅡ) Hangul jungseong a (base code point) 11A8 (ᄀ) Hangul jongseong kiyeok (base code point) |
|
|
64 (d) Latin small letter d (base code point) 325 ( ̥ ) combining ring below (non-spacing mark) 301 ( ́ ) combining acute accent (non-spacing mark) |
|
á |
61 (a) Latin small letter a (base code point) 301 ( ́ ) combining acute accent (non-spacing mark) |
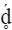
Some common multiple code point graphemes have been combined into a single code point. For example, the last entry in the table above, á, can also be represented by the single code point E1. Hence we have two representations, or two graphemes, that represent the same character (á in this case).
Index Terms
An index term is the basic unit for searching. It is a sequence of one or more graphemes that can be found in a search but for which searching of sub-parts is not supported (except if regular expressions are used). EMu provides word based searching, so an index term corresponds to a word. You can search for a word, and records that contain that word will be matched. In languages that define a word as a sequence of letters separated by either spaces or punctuation, an index term corresponds to a word. In languages in which single (or sometimes multiple) letters make up a word, such as kanji, an index term corresponds to each individual letter. EMu 5.0 added support for searching for punctuation, so each punctuation character is considered to be an index term.
Consider the following text:
香港 is Chinese for "Hong Kong" (香 = fragrant, 港 = harbour).
The index terms for the above text are:
| Index Term |
|---|
|
香 |
|
港 |
|
is |
|
Chinese |
|
for |
|
" |
|
Hong |
|
Kong |
|
" |
|
( |
|
香 |
|
= |
|
fragrant |
|
, |
|
港 |
|
= |
|
harbour |
|
) |
|
. |
Each of the above terms can be used in a search and the query will be able to use the high speed indexes to locate the matching records. It is possible to use regular expression characters (e.g. fra\* to find all words beginning with fra) to search for sub-parts of words, however the high speed indexes will not be used in this case (unless partial indexing is enabled).
Each index term is folded and converted to its base form. The folding process, as described earlier, removes case significance from the term. The conversion to its base form involves removing all "mark" code points from the term and then converting the remaining code points to their compatible form (as defined by the Unicode 8.0 standard). The compatible form for a code point is a mapping from the current code point to a base character that has the same meaning. For example the code point for subscript 5 (5) has a compatible code point of 5.
The table below shows some more examples for compatibility:
| Type | Compatibility Examples | ||
|---|---|---|---|
|
Font variants |
H | à | H |
| H | à | H | |
|
Positional variants |
ع | à | ع |
| ﻊ | à | ع | |
| ﻋ | à | ع | |
| ﻌ | à | ع | |
|
Circled variants |
| à | 1 |
|
Width variants |
カ | à | カ |
|
Rotated variants |
︷ | à | { |
| ︸ | à | } | |
|
Superscripts / subscripts |
i9 | à | i9 |
| i9 | à | i9 | |
Unfortunately, some of the compatibility mappings in the Unicode 8.0 standard are narrower than we might expect when searching text. For example the oe ligature (œ) does not map to the characters "oe". So the French word cœur ("heart") does not have an index term of coeur, but remains as cœur. When searching you need to enter cœur as the search term otherwise cœur will not be found.
In order to correct some of the compatibility mappings, EMu 1 provides a mapping file where a code point can be mapped to its compatible code point(s), hence "œ" can be mapped to "oe". The mapping file is located in the Texpress installation directory in the etc/unicode/base.map file.
# # The following file is used to extend the Unicode NFKD mappings for # characters not specified in the standard. The format of the file is # a sequence of numbers as hex. Each number represents a single code # point in UTF-32 format. The first code point is the code point to map # and the second and subsequent code points are what it maps to. # 00C6 0041 0045 # Latin capital letter AE -> A E 00E6 0061 0065 # Latin small letter ae -> a e 00D0 0044 # Latin capital letter Eth -> D 00F0 0064 # Latin small letter eth -> d 00D8 004F # Latin capital letter O with stroke -> O 00F8 006F # Latin small letter o with stroke -> o 00DE 0054 0068 # Latin capital letter Thorn -> Th 00FE 0074 0068 # Latin small letter thorn -> th 0110 0044 # Latin capital letter D with stroke -> D 0111 0064 # Latin small letter d with stroke -> d 0126 0048 # Latin capital letter H with stroke -> H 0127 0068 # Latin small letter h with stroke -> h 0131 0069 # Latin small letter dotless i -> i 0138 006B # Latin small letter kra -> k 0141 004C # Latin capital letter L with stroke -> L 0142 006C # Latin small letter l with stroke -> l 014A 004E # Latin capital letter Eng -> N 014B 006E # Latin small letter eng -> n 0152 004F 0045 # Latin capital ligature OE -> O E 0153 006F 0065 # Latin small ligature oe -> o e 0166 0054 # Latin capital letter T with stroke -> T 0167 0074 # Latin small letter t with stroke -> t
Compatible mappings may be added to the file as required.
Note: If the file is modified, a complete reindex of the system is required in order for the new mappings to be used to calculate the index terms.
If you consider the French phrase:
Sacré-Cœur est situé à Paris.
the index terms after folding and conversion to base form are:
|
Index Term |
|---|
|
sacre |
|
coeur |
|
est |
|
situe |
|
a |
|
paris |
|
. |
When a record is saved in EMu all index terms are folded and converted to their base form before indexing occurs. Similarly, when a search is performed, the query terms are folded and converted to their base form before the search commences. Hence a search for "coeur" or "Cœur" or even "COEUR" will still match the text in the French phrase above.
Auto-Phrasing
Unicode graphemes are broken down into one of three categories for use in EMu.
The categories are:
| Category | Description |
|---|---|
| combining |
A grapheme that is a simple letter or number. It is not a word in its own right but requires other characters to form words. Examples are the Latin, Arabic and Hebrew letters and numbers. |
| single |
A single grapheme is used to represent a base word or meaning. Examples are Kanji and punctuation characters. |
| break |
A character that delineates words, typically a space character. |
Consider the following text:
香港 = "Hong Kong".
The graphemes along with categories are:
| Grapheme | Category |
|---|---|
|
香 |
single |
|
港 |
single |
|
|
break |
|
= |
single |
|
|
break |
|
" |
single |
|
H |
combining |
|
o |
combining |
|
n |
combining |
|
g |
combining |
|
|
break |
|
K |
combining |
|
o |
combining |
|
n |
combining |
|
g |
combining |
|
" |
single |
|
. |
single |
EMu uses the category to determine what is an index term. Each single grapheme is treated as a separate index item, while combining graphemes are joined together to form a "word" up to a break or single category grapheme. A break grapheme is not an index term and is discarded.
In general, a phrase-based search must be performed where you want to find records where a list of index terms occur sequentially. For example, to find the two kanji characters 香港 (Hong Kong) next to each other, the query \"香 港\" may be used. Where a grapheme is part of the single category (like the two kanji characters), the system knows what the index term is and is able to treat them as a phrase provided a break character is not found. In fact EMu treats a combination of combining and single graphemes as a phrase without the need for the phrase operator until a break grapheme is encountered. This process is known as auto-phrasing.
Auto-phrasing means that a query of 香港 is equivalent to \"香港\" without the need to add the quotes or space. Another example is an email address such as fred@global.com. In this case the index terms fred, @, global, ., com must be located sequentially. Auto-phrasing effectively allows you to enter non-space separated terms and EMu will retrieve records where the terms are adjacent. If you do not want the terms to appear next to each other, for example if you want to find 香 (fragrant) 港 (harbour), then simply placing a space between the two kanji characters will disable auto-phrasing.
Collation
Collation is the general term for the process of determining the sorting order of strings of characters. EMu 5.0 onwards uses the Default Unicode Collation Element Table (DUCET), as defined in the Unicode 8.0 standard, to determine how text should be sorted. DUCET provides a locale independent mechanism for ordering values.
If you are interested in the ordering used by DUCET, please consult the Unicode Collation Chart.

