Bucket selection methods
When determining what range buckets to use
Distribution method
The distribution method tries to allocate the same number of values to each range bucket. The result is an even distribution of the values over the entire set of range bucket values. For example, if we have the following data distribution:
Value Count
===== =====
1959:1:20 1
1973:3:8 1
1974:3:8 1
1975:2:11 3
1977:: 3
1977:2:8 1
1981:: 1
1982:11:8 1
1983:4:12 3
1983:5:9 1
1984:9:11 1
1985:: 1
1985:6:12 1
1986:2:11 1
1986:6:17 1
1986:9: 1
1988:6:28 2
1989:1: 2
1995:6:6 1
1995:9: 1
1996:2: 1
1996:2:28 4
1996:4:3 1
1996:9:17 1
1997:8:20 1
2003:10:17 1
Distinct 26
Total 37
we get the following range buckets calculated:
Range Buckets (distribution)
=============
1977-2-8
1986-2-11
1996-2-1
The graphic below shows the values per bucket:
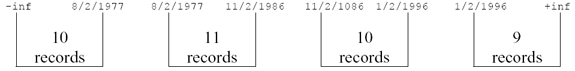
The distribution method provides optimal searching where the query ranges are not known in advance and where a reasonable spread of query ranges is expected. As equal numbers of records are placed in each range bucket the index will generally provide reasonable performance for any given query. The distribution method is the default method used by
Interval method
The interval method takes a different approach to the distribution method. Rather than ensuring that an equal number of records is allocated to each range bucket, the interval method generates equal intervals between each bucket value. It does this by taking the difference between the minimum value and the maximum value and apportioning it between the specified number of bucket intervals. So for the data distribution provided for the distribution method the generated intervals are:
Range Buckets (interval)
=============
1970-3-27
1981-6-3
1992-8-10
The graphic below gives the intervals:
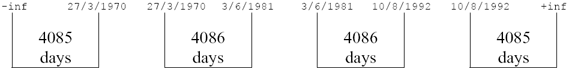
The advantage of the interval method is that it gives a decent set of range buckets when data is not available for a given field (generally because it has not been entered or imported). It also provides buckets that may be more in line with query ranges that correspond to fixed intervals (e.g. year ranges for date searches, hour intervals for time searches, etc.) and so gives better performance where query range intervals are commonly used. Interval ranges can be generated by specifying the -i option to
Partition method
The partition method is similar to the distribution method, however rather than ensuring that equal numbers of records are in each range bucket it ensures that equal numbers of unique values are in each range bucket (if ten values are the same, they are distributed as a single value). For the data distribution provided for the distribution method the generated partitions are:
Range Buckets (partition)
=============
1981-1-1
1986-2-11
1996-2-1
The graphic below shows the number of distinct values for each range bucket:

The partition method is useful when a good distribution of buckets is required that takes into account the values that have already been entered without giving undue influence to the weighting of each value (as is the case with the distribution method). In general this method will provide good "all-round" performance as it gives sensible range intervals based on the data already entered. Partition ranges can be generated by specifying the -p option to