Texpress : optimiser et configurer le moteur de base de données
L'indexation optimale des tables de la base de données peut être réalisée à l'aide du sous-système de configuration de Texpress1. Une suite d'outils est fournie pour vérifier l'efficacité des configurations et pour générer de nouvelles configurations. Il est également possible de sauvegarder les configurations par table afin que les paramètres ne soient pas perdus lors de la prochaine reconfiguration automatisée.
La première partie de ce qui suit est une explication assez technique du mécanisme d'indexation de Texpress ; bien que difficile, elle peut s'avérer utile lors de l'exécution de la dernière étape (facultative) Étape 7 : Sauvegarder les paramètres de configuration lors de l'optimisation de Texpress. Vos paramètres de configuration sont stockés dans un fichier params. La partie 1 de ce document explique en détail comment sont calculés les différents éléments du fichier params.
Dans la deuxième partie, Outils de configuration, vous trouverez des informations importantes sur les outils de configuration disponibles pour optimiser et configurer le moteur de base de données :
Les outils de configuration qui permettent une indexation optimale des tables Texpress ont été révisés avec Texpress 8.2.01.
En raison de l'approche simpliste de la configuration automatique adoptée par les versions antérieures de Texpress, l'obtention de performances optimales pour une table relevait de la magie noire. Par conséquent, les performances n’étaient pas optimales, en particulier pour les très grands ensembles de données. Dans de nombreux cas, la configuration manuelle était le seul moyen d'obtenir des performances quasi optimales. La plupart des problèmes de configuration résultaient d'hypothèses applicables aux ensembles de données avec une distribution normale des tailles d'enregistrement, mais qui ne tenaient pas pour les divers ensembles de données trouvés dans une installation EMu « normale ». En particulier, lorsque les données étaient chargées à partir d'un certain nombre d'anciens systèmes divers, la distribution des tailles d'enregistrement ne suivait pas une distribution normale unique, mais ressemblait à un certain nombre d'ensembles de données normalement distribués, un par ancien système, se superposant les uns aux autres. L'histogramme ci-dessous montre la distribution des tailles d'enregistrement pour le module Personnes / Organisations :
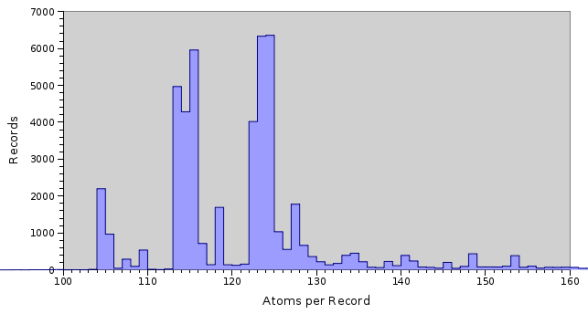
Comme vous pouvez le constater, la distribution des tailles d'enregistrement ne suit pas une distribution normale. Cependant, si vous regardez de près, vous remarquerez que l'histogramme est composé de trois distributions normales, avec des centres à 105, 115 et 125, superposés les uns aux autres. Chacune de ces distributions reflète les données d'un ancien système. Nous avons donc trois sources de données différentes où chaque source de données est distribuée normalement, mais où l'ensemble des données combinées ne l'est pas !
Avant Texpress 8.2.01, les outils de configuration automatisés supposaient que l'ensemble des données suivait une distribution normale et produisaient des index basés sur cette hypothèse. Le résultat final est que dans les ensembles de données distribuées non normales, de mauvais paramètres d'indexation ont été utilisés, ce qui a entraîné des temps de réponse lents et un nombre excessif de fausses correspondances. La nouvelle fonction de configuration fournie avec Texpress 8.2.01 s'adapte à toutes les distributions d'ensembles de données tout en offrant une vitesse de requête optimale avec une utilisation minimale du disque.
Ce qui suit est un examen détaillé des paramètres d’entrée du processus de configuration, car une bonne compréhension de ces valeurs permet une configuration manuelle ciblée si besoin. Tout d'abord, nous devons commencer par les bases.
Texpress utilise un Système de codage superposé à deux niveaux pour la recherche de correspondances partielles comme principal mécanisme d'indexation. Nous explorons ici ce que nous entendons par Schéma de codage superposé et examinons les variables qui affectent la configuration optimale.
Le schéma est composé de deux parties : la première est un schéma de codage, et la seconde est le mécanisme de superposition. Pour expliquer le fonctionnement de ces stratégies, un exemple concret sera utilisé. Pour l'exemple, nous supposerons que nous avons un enregistrement Personnes / Organisations simple avec les données suivantes :
|
Nom du champ |
Valeur |
|---|---|
| Prénom | Boris
|
| Nom | Badenov
|
| Ville | FrostBite Falls
|
| État | Minnesota
|
Schéma de codage
La première partie de l'algorithme d'indexation consiste à coder chacune des valeurs du champ en une chaîne de bits, c'est-à-dire une séquence de bits zéro et un. Deux variables sont utilisées lors de l'encodage d'une valeur. La première est k, qui est le nombre de 1 dont nous avons besoin pour la valeur et le second est b, qui est la longueur de la chaîne de bits. Les variables b et k sont les deux premières entrées dans la configuration du mécanisme d'indexation.
Pour coder une valeur, nous utilisons un générateur de nombres pseudo-aléatoires. Nous devons appeler le générateur k fois et la valeur résultante doit être comprise entre 0 et b - 1. Pour chaque nombre généré, nous convertissons la position du bit en un 1. La caractéristique importante d'un générateur de nombres pseudo-aléatoires est que si nous fournissons les mêmes entrées (c'est-à-dire les mêmes k, b et valeur), les mêmes k nombres seront générés, donc les mêmes entrées produiront toujours les mêmes sorties. Supposons que nous utilisions k=2 et b=15 pour coder notre enregistrement de test. La table ci-dessous présente des exemples de chaînes de bits générées pour les valeurs données b et k :
| Valeur |
Positions des bits |
Chaîne de bits |
|---|---|---|
Boris
|
3, 10 | 00010 00000 10000 |
Badenov
|
1, 4 | 01001 00000 00000 |
FrostBite
|
3, 7 | 00010 00100 00000 |
Falls
|
8, 14 | 00000 00010 00001 |
Minnesota
|
4, 9 | 00001 00001 00000 |
Remarquez comment les deux mots du champ Ville sont codés séparément. C'est ce codage distinct qui permet de prendre en charge la recherche par mot, c'est-à-dire la recherche où un seul mot est spécifié. Le générateur de nombres pseudo-aléatoires utilisé par Texpress requiert également une autre entrée, le numéro de colonne de la valeur à indexer. La raison de cette entrée est que le même mot dans différentes colonnes devrait donner lieu à des chaînes de bits différentes. Sinon une recherche sur ce mot le trouverait dans toutes les colonnes (c'est ainsi que la fonction Rechercher aussi est mise en œuvre, où chaque colonne Rechercher aussi utilise le même numéro de colonne, celui de la colonne d'origine).
Schéma superposé
Une fois que toutes les chaînes de bits sont générées, elles sont combinées par OU pour produire la chaîne de bits finale. La chaîne de bits est appelée descripteur d'enregistrement, car elle contient une version codée des données de l'enregistrement, en d'autres termes, elle décrit le contenu de l'enregistrement sous la forme d'une chaîne de bits. En utilisant notre exemple, le descripteur d'enregistrement résultant serait :
|
00010 00000 10000 |
OU |
|
01001 00000 00000 |
|
|
00010 00100 00000 |
|
|
00000 00010 00001 |
|
|
00001 00001 00000 |
|
|
01011 00111 10001 |
|
Fausses correspondances
Le système d'indexation utilisé par Texpress peut indiquer qu'un enregistrement correspond à une requête alors que ce n'est pas le cas. Ces fausses correspondances sont dues au mécanisme d'encodage utilisé. Lorsqu'une requête est effectuée, le terme de la requête est codé en une chaîne de bits comme décrit ci-dessus. Le descripteur d'enregistrement résultant, généralement connu sous le nom de descripteur de requête, est soumis à une opération ET avec chaque descripteur d'enregistrement et, lorsque le descripteur résultant est identique au descripteur de requête, l'enregistrement correspond (c'est-à-dire que le descripteur d'enregistrement a un 1 dans chaque position où le descripteur d'interrogation a un 1). En utilisant notre exemple ci-dessus, supposons que nous recherchons le terme Boris. Nous codons le terme et le comparons au descripteur de l'enregistrement :
|
00010 00000 10000 |
ET |
( |
|
01011 00111 10001 |
|
(descripteur d'enregistrement) |
|
00010 00000 10000 |
|
(Descripteur résultant) |
Étant donné que le descripteur résultant est le même que le descripteur de la requête, l'enregistrement est marqué comme une correspondance. Considérons maintenant la recherche de Natasha. Afin de démontrer une fausse correspondance, supposons que Natasha est codé comme suit :
| Valeur |
Positions des bits |
Chaîne de bits |
|---|---|---|
|
|
7, 9 |
00000 00101 00000 |
Lorsque nous effectuons notre recherche, nous obtenons :
|
00000 00101 00000 |
ET |
( |
|
01011 00111 10001 |
|
(descripteur d'enregistrement) |
|
00000 00101 00000 |
|
(Descripteur résultant) |
Comme vous pouvez le constater, le descripteur de requête est le même que le descripteur résultant. Il semble donc que les enregistrements correspondent, sauf que l'enregistrement du descripteur 01011 00111 10001 ne contient pas Natasha. C'est ce qu'on appelle une fausse correspondance. Afin de « masquer » les fausses correspondances aux utilisateurs, Texpress vérifie chaque enregistrement avant de l'afficher pour confirmer qu'elle contient bien le ou les termes de requête spécifiés. Si ce n'est pas le cas, l’enregistrement est retiré de l'ensemble des correspondances.
La raison de ces fausses correspondances est qu'une combinaison des bits définis pour une série de termes dans un enregistrement fait apparaître des 1 dans les mêmes positions que pour un seul terme. En utilisant notre exemple, vous pouvez voir que Frostbite génère le bit sept et que Minnesota génère le bit neuf, qui se trouvent correspondre aux bits générés par Natasha. Afin d'assurer une requête précise, nous devons réduire au minimum le nombre de fausses correspondances.
Calcul de k et b
Maintenant que nous avons vu comment fonctionne le schéma de codage superposé, c'est-à-dire en traduisant le contenu d'un enregistrement en un descripteur d'enregistrement, nous devons étudier comment calculer k (nombre de bits à définir pour 1 par terme) et b (longueur de la chaîne de bits). La première variable que nous allons examiner est k. Afin de calculer k, nous devons introduire deux nouvelles variables :
|
d |
La densité de bits est le rapport entre le nombre de bits 1 définis et la longueur du descripteur. La valeur est exprimée en pourcentage. Par exemple, une densité binaire de 25 % indique qu'un bit sur quatre sera égal à 1, les trois autres étant des 0, lorsqu'on fait la moyenne sur l'ensemble du descripteur d'enregistrement. Si nous utilisons notre exemple de descripteur d'enregistrement de 01011 00111 10001, il y a huit bits 1 sur un total de 15 bits, ce qui donne une densité binaire de 8/15 ou 53 %. Texpress utilise une valeur de densité binaire par défaut de 25 %. |
|
f |
La probabilité de fausse correspondance est le nombre de descripteurs d'enregistrements que nous devons examiner pour obtenir une fausse correspondance. Par exemple, une valeur de 1024 indique que nous nous attendons à avoir une fausse correspondance pour chaque 1024 descripteurs d'enregistrement vérifiés lors de la requête. Grâce à cette variable, nous pouvons configurer le système pour qu'il fournisse un niveau « acceptable » de fausses correspondances. Texpress utilise la valeur 1024 pour la probabilité de fausse correspondance pour les descripteurs d'enregistrements. |
Le nombre de bits que nous devons définir pour un terme est lié à la fois à la probabilité de fausse correspondance et à la densité de bits. Si nous utilisons une densité de bits de 25 %, un bit sur quatre est défini sur 1 dans notre descripteur d'enregistrement. Cela implique que la probabilité qu'un bit donné soit un 1 est de 1/4. Si k est défini sur 1, un bit est donc généré par terme, la probabilité que le bit soit déjà défini est de 1/4. Si deux bits sont activés (k=2), la probabilité que les deux bits soient définis est de 1/4 * 1/4 = 1/16. La table ci-dessous donne plus de détails :
|
k |
Probabilité que tous les bits soient définis sur un |
Valeur |
|---|---|---|
| 1 | 1/4 | 1/4 |
| 2 | 1/4 * 1/4 | 1/16 |
| 3 | 1/4 * 1/4 * 1/4 | 1/64 |
| 4 | 1/4 * 1/4 * 1/4 * 1/4 | 1/256 |
| 5 | 1/4 * 1/4 * 1/4 * 1/4 * 1/4 | 1/1024 |
| 6 | 1/4 * 1/4 * 1/4 * 1/4 * 1/4 * 1/4 | 1/4096 |
Si la probabilité de fausse correspondance est fixée à 1024 (comme utilisé par Texpress), vous pouvez voir dans la table ci-dessus que nous devons fixer k à 5. La raison pour laquelle la valeur cinq est sélectionnée est que, pour obtenir une fausse correspondance, tous les bits du terme dont la requête est faite doivent être définis sur un, mais ne doivent pas contenir le terme. Ainsi, si k est égal à cinq, nous avons une chance sur 1024 qu'un descripteur d'enregistrement ne corresponde pas correctement. Si nous diminuons la densité de bits à, disons, 12,5 % ou un bit sur huit, une valeur de quatre pour k est suffisante, comme le montre la table ci-dessous :
|
k |
Probabilité que tous les bits soient définis sur un |
Valeur |
|---|---|---|
|
1 |
1/8 |
1/8 |
|
2 |
1/8 * 1/8 |
1/64 |
|
3 |
1/8 * 1/8 * 1/8 |
1/512 |
|
4 |
1/8 * 1/8 * 1/8 * 1/8 |
1/4096 |
Il est facile de voir que si nous diminuons la densité de bits (d), nous diminuons également la valeur de k. Nous pouvons exprimer la relation entre k, f et d comme suit :
f = (100 / d)k
Avec un peu de calcul, nous pouvons isoler k de la formule ci-dessus, ce qui donne :
k = log(f) / log(100 / d)
Maintenant que k est calculé, nous pouvons l'utiliser pour déterminer la valeur de b (la longueur de la chaîne de bits). Nous devons introduire une nouvelle variable afin de calculer b :
|
i |
Le nombre d'atomes indexés par enregistrement définit le nombre de valeurs à encoder dans le descripteur d'enregistrement. Dans notre exemple, la valeur de i est de cinq car nous avons cinq termes encodés dans le descripteur de l'enregistrement ( |
En utilisant la valeur de i, nous pouvons calculer la valeur de b. En utilisant une approche simpliste, nous pourrions prendre la valeur de k (bits à définir par terme) et la multiplier par i (nombre de termes) pour obtenir le nombre de bits définis sur 1. Si nous supposons que d (densité de bits) est de 25 %, nous devons multiplier le nombre de 1 définis par quatre pour obtenir la valeur de b. Exprimé sous forme de formule, on obtient (i * k * (100/d)). En utilisant notre exemple, nous aurions :
5 * 5 * (100 / 25) = 100 bitsAinsi, pour notre exemple d'enregistrement, nous aurions la configuration suivante :
|
Variable |
Description |
Valeur |
|---|---|---|
|
f |
Probabilité de fausse correspondance |
1024 |
|
d |
Densité de bits |
25 % |
|
i |
Termes indexés par enregistrement |
5 |
|
k |
Bits définis par terme |
5 |
|
b |
Longueur de la chaîne de bits (en bits) |
100 |
En réalité, la formule utilisée pour calculer b est un peu simpliste. Elle est utile en tant qu'approximation, mais elle n'est pas totalement exacte. Lorsque nous construisons le descripteur d'un enregistrement, nous utilisons le générateur de nombres pseudo-aléatoires pour calculer k bits par terme. Si nous avons i termes, nous appelons le générateur de nombres pseudo-aléatoires i fois, une fois pour chaque terme. Chaque terme définira les bits k/b. Ainsi, pour chaque terme, la probabilité qu'un bit soit encore 0 est (1 - k/b), donc pour les termes i la probabilité qu'un bit soit encore 0 est (1 - k/b)i. De ce fait la probabilité qu'un bit soit 1 doit être (1 - (1 - k/b)i). Nous savons également que la probabilité qu'un bit soit 1 doit être (d/100), c'est-à-dire le nombre de bits 1 sur la base de la densité binaire. On se retrouve donc avec :
1 - (1 - k/b)i = d / 100
Maintenant, avec un peu de calcul, nous pouvons isoler b de la formule ci-dessus, ce qui donne :
b = k / (1 - exp(log((100 - d) / 100) / i))
En utilisant la formule ci-dessus pour b avec notre exemple d’enregistrement, nous obtenons une valeur de 90 bits au lieu des 100 calculés par la méthode simpliste. Si vous n'avez pas compris la façon dont b était calculé, ce n'est pas important, sauf pour comprendre que Texpress utilise cette dernière formule pour déterminer b. Maintenant que les concepts clés sont en place et que nous avons examiné les variables utilisées pour calculer le nombre de bits à définir par terme (k) et la longueur de la chaîne de bits (b), nous devons examiner ce que nous entendons par Deux niveaux lorsque nous parlons d'un Schéma de codage à deux niveaux pour la récupération des correspondances partielles.
Comme vous pouvez l'imaginer, un système d'indexation à deux niveaux doit comporter deux parties, et c'est effectivement le cas. Heureusement, les deux parties sont très similaires et utilisent la théorie couverte dans la dernière section. Le premier niveau est le niveau du descripteur de segment et le second est le niveau du descripteur d'enregistrement :
|
Descripteur de segment |
Un descripteur de segment est une chaîne de bits qui code des informations pour un nombre fixe d'enregistrements. Il utilise la théorie présentée ci-dessus, sauf qu'un descripteur de segment simple décrit un groupe d'enregistrements plutôt qu'un enregistrement unique. Le nombre d'enregistrements dans un segment fait partie de la configuration du système et est connu sous le nom de Nr. Une valeur typique pour Nr est d'environ 10. Les descripteurs de segment sont stockés de manière séquentielle dans le fichier |
|
Descripteur d'enregistrement |
Le niveau Descripteurs d'enregistrement contient un descripteur d'enregistrement par enregistrement. Les descripteurs d'enregistrements sont regroupés en lots de Nr. Les lots sont stockés les uns après les autres dans le fichier |
La table ci-dessous montre la relation entre les descripteurs de segments et les descripteurs d'enregistrements où Nr est 4 :
|
Descripteur de segment 1 |
Descripteur d'enregistrement 1 |
|
Descripteur d'enregistrement 2 |
|
|
Descripteur d'enregistrement 3 |
|
|
Descripteur d'enregistrement 4 |
|
|
Descripteur de segment 2 |
Descripteur d'enregistrement 5 |
|
Descripteur d'enregistrement 6 |
|
|
Descripteur d'enregistrement 7 |
|
|
Descripteur d'enregistrement 8 |
|
|
… |
… |
Les descripteurs de segments sont consultés en premier lorsqu'une recherche est effectuée. Pour chaque descripteur de segment correspondant, les Nr descripteurs d'enregistrement correspondants sont vérifiés pour trouver le ou les enregistrements correspondants. Pour chaque descripteur de segment qui ne correspond pas, les Nr descripteurs d'enregistrement associés peuvent être ignorés. En substance, nous nous retrouvons avec un système qui peut très rapidement écarter les enregistrements qui ne correspondent pas, laissant ceux qui correspondent.
Calcul d'une valeur pour Nr
Il peut être tentant de fixer le nombre d'enregistrements dans un segment à un nombre très élevé. Après tout, si le descripteur du segment ne correspond pas, cela signifie que les Nr enregistrements peuvent être rapidement écartés. Jusqu'à un certain point, c'est correct. Cependant, plus le nombre d'enregistrements par segment est important, plus la probabilité qu'un segment donné contienne une correspondance est élevée. Par exemple, supposons que nous avons 100 enregistrements par segment. Les données de 100 enregistrements sont encodées dans chaque descripteur de segment et les descripteurs d'enregistrements sont regroupés par lots de 100. Supposons maintenant que notre base de données contienne 500 enregistrements et que nous recherchions un terme qui donnera lieu à une seule correspondance. Il est clair dans ce cas qu'un seul descripteur de segment correspondra (en supposant qu'il n'y a pas de fausses correspondances), nous devons donc rechercher dans 100 descripteurs d'enregistrement pour trouver l'enregistrement correspondant. Si le nombre d'enregistrements par segment était de 10, nous obtiendrions toujours une correspondance au niveau du segment, mais il nous suffirait de parcourir 10 descripteurs d'enregistrement pour trouver l'enregistrement correspondant.
Le réglage du nombre d'enregistrements par segment permet d'équilibrer le rejet rapide d'un grand nombre d'enregistrements (en fixant une valeur élevée) et le temps nécessaire à la recherche des descripteurs d'enregistrements dans un segment si celui-ci correspond (en fixant une valeur faible). Il faut également tenir compte des requêtes à termes multiples. Puisqu'un descripteur de segment encode les termes d'un certain nombre d'enregistrements, une requête multi-termes qui contient tous les termes de la requête répartis sur les enregistrements du segment correspondra au niveau du segment, ce qui oblige à vérifier les descripteurs d'enregistrement. Par exemple, si les termes recherchés sont red et house et que le premier enregistrement d'un segment contient le mot red, tandis que le troisième enregistrement contient le mot house, alors le descripteur du segment correspondra (car il code les deux mots). On consulte ensuite les descripteurs d’enregistrements pour voir si certains enregistrements contiennent les deux termes. Comme il n'existe pas d'enregistrement correspondant dans le segment, du temps a été « perdu » à chercher une correspondance inexistante.
Pour déterminer la meilleure valeur pour le nombre d'enregistrements dans un segment, il est important de comprendre comment la base de données sera interrogée. En particulier, si l'on s'attend à un grand nombre de recherches sur un seul terme, il est logique d'avoir un nombre raisonnablement élevé d'enregistrements par segment (disons environ 20-50). Si des recherches multi-termes sont utilisées et que les termes recherchés sont soit liés, soit distincts (c'est-à-dire qu'ils ne se retrouvent pas dans de nombreux enregistrements), la valeur peut également être élevée. Par exemple, le module Taxonomie se compose principalement de termes associés (la Hiérarchie de classification). En cas de recherche d’une combinaison genre-espèce, il est très probable que les deux termes apparaîtront dans le même enregistrement (puisqu'une espèce est un terme plus restreint d'un genre).
Si, toutefois, les requêtes multi-termes contiennent des termes communs non apparentés, une valeur plus petite pour les enregistrements par segment est nécessaire. Par exemple, le module Personnes / Organisations contient des enregistrements qui ont de nombreux termes communs. Imaginez une recherche de tous les artistes de Londres (c'est-à-dire Rôle=artist et Ville=London). Il y a probablement beaucoup d'enregistrements pour lesquels le champ Rôle contient artist, de même que de nombreux enregistrements peuvent avoir une valeur Ville de London. Cependant, il se peut qu'il n'y ait pas beaucoup d'enregistrements qui contiennent les deux termes. Si le nombre d'enregistrements par segment est élevé, un grand nombre de correspondances de segments se produira (parce qu'au moins un enregistrement du segment a un Rôle de artist et qu'au moins un autre enregistrement du segment a une valeur Ville de London). Dans ce cas, il est préférable de fixer le nombre d'enregistrements par segment à un niveau faible, disons environ 10. La configuration de Texpress utilisera une valeur proche de 10 pour le nombre d'enregistrements par segment, car cela permet d'obtenir un index général sans connaissance des données et des requêtes attendues.
Il existe une autre variable utilisée pour déterminer le nombre d'enregistrements dans un segment, la taille de bloc système :
|
taille du bloc |
La taille de bloc est le nombre d'octets qui sont lus ou écrits en une seule fois lors de l'accès à un système de fichiers. Tous les accès au disque du système de fichiers se font en utilisant ce nombre fixe d'octets. Même si vous lisez un octet, le système de fichiers sous-jacent lira toujours des octets de taille de bloc et vous renverra l'octet unique. La taille de bloc d'un système de fichiers est définie lors de la création du système de fichiers. Les tailles de bloc les plus courantes sont 1 024, 4 096 ou 8 192 octets. Texpress assume une taille de bloc par défaut de 4 096 octets. |
Afin de permettre une recherche efficace, il est important de s'assurer que toute l'activité du disque se déroule en multiples de la taille de bloc du système de fichiers. Ainsi, lorsque nous sélectionnons le nombre d'enregistrements dans un segment, nous devons nous assurer que la valeur sélectionnée remplit un nombre entier de blocs. Si nous reprenons notre exemple, nous avons vu que la valeur de b (longueur de la chaîne de bits) était de 90 bits ou 12 octets (en arrondissant au chiffre supérieur). Si la taille du bloc est de 4 096 octets, un bloc de disque peut contenir 341 descripteurs d'enregistrement (4 096/12 arrondis au chiffre inférieur). Ainsi, pour notre échantillon de données, la valeur de Nr serait de 341. Comme notre exemple ne comporte que cinq termes, cela conduit à une valeur très élevée. Dans la pratique, les enregistrements contiennent beaucoup plus de termes. Le nombre d'enregistrements par segment est donc généralement d'environ 10 par défaut.
Découpage en bits
La dernière pièce du puzzle de l'indexation est l'utilisation du découpage en bits pour fournir un mécanisme de recherche rapide dans le fichier des descripteurs de segments. Comme nous l'avons vu, un descripteur de segment encode les informations d’enregistrements Nr dans un descripteur. Les descripteurs sont stockés les uns après les autres dans le fichier seg dans le répertoire de la base de données. Lorsqu'une requête est effectuée, la première étape consiste à rechercher chaque descripteur de segment en l'associant par ET au descripteur de segment de la requête pour voir s'il correspond. Lorsque nous obtenons une correspondance, nous vérifions ensuite les descripteurs d'enregistrement de la même manière. Le problème de cette approche est que le fichier seg peut être très volumineux et qu'une recherche séquentielle dans ce fichier peut prendre un certain temps. Le schéma ci-dessous montre une série de descripteurs de segments et un descripteur de requête utilisé pour la recherche :
|
1 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
1 |
0 |
… |
(Descripteur de segment 1) |
|
0 |
1 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
0 |
… |
(Descripteur de segment 2) |
|
1 |
1 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
… |
(Descripteur de segment 3) |
|
0 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
0 |
… |
(Descripteur de segment 4) |
|
… |
|
|
|
|
|
|
|
|
|
|
(Descripteur de segment N) |
|
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
… |
(Descripteur de segment d'interrogation arbitraire) |
Il est évident, d'après la table ci-dessus, que pour qu'un descripteur de segment corresponde au descripteur de segment de la requête, il faut un bit 1 dans chaque position où le descripteur de requête a un bit 1. Les autres bits du descripteur ne sont pas pertinents. À l'aide de cette information, le moyen le plus rapide de déterminer quels descripteurs de segment correspondent est de lire des tranches des descripteurs de segment. Lorsque le descripteur de segment de la requête a un bit 1, nous lisons une tranche (c'est-à-dire un bit de chaque descripteur de segment). La tranche est représentée par la zone jaune délimitée par les lignes dans le diagramme. Si nous lisons une tranche pour chaque bit 1 du descripteur de requête et que nous les ajoutons ensemble avec ET, tout bit 1 résultant doit contenir la position d'un descripteur de segment dont tous les bits 1 sont également définis. Dans l'exemple ci-dessus, seul le descripteur de segment 1 correspond au descripteur de segment de la requête.
Le problème de cette approche est que la lecture de bits individuels à partir d'un système de fichiers est extrêmement inefficace. Vous remarquerez cependant que si nous « retournons » le fichier des descripteurs de segments sur le côté, chaque tranche peut maintenant être lue avec un seul accès au disque. La table ci-dessous montre les descripteurs de segment « retournés » :
|
1 |
0 |
1 |
0 |
… |
|
0 |
1 |
1 |
0 |
… |
|
1 |
0 |
1 |
0 |
… |
|
1 |
1 |
0 |
1 |
… |
|
0 |
0 |
0 |
1 |
… |
|
1 |
0 |
0 |
0 |
… |
|
1 |
1 |
0 |
0 |
… |
|
0 |
1 |
1 |
1 |
… |
|
1 |
0 |
0 |
1 |
… |
|
0 |
0 |
1 |
0 |
… |
Si nous prenons les tranches que nous devons vérifier et que nous les associons avec ET, lorsqu'un bit 1 est activé dans la tranche résultante, le numéro du segment correspond au descripteur de segment de la requête :
|
1 |
0 |
1 |
0 |
… |
ET |
|
1 |
1 |
0 |
0 |
… |
|
|
1 |
0 |
0 |
0 |
… |
|
D'après notre configuration d'origine, nous savons que nous définissons k bits par terme, donc si une requête d'un seul terme est effectuée, nous devons lire k tranches de bits pour déterminer quels segments correspondent à la requête. Le découpage en bits du fichier de segments est la raison pour laquelle Texpress a une vitesse d'interrogation exceptionnelle.
Un des problèmes du découpage en bits du fichier des descripteurs de segments est que pour stocker les tranches de bits de manière séquentielle, nous devons connaître la longueur d'une tranche de bits. Nous connaissons la longueur du descripteur de segment, elle est de b, donc b tranches de bits sont stockées dans le fichier ; mais quelle est la longueur de chaque tranche ? Afin de déterminer la longueur d'une tranche de bits, nous devons connaître la capacité de la base de données, c'est-à-dire le nombre d'enregistrements qui seront stockés. En utilisant le nombre d'enregistrements par segment (Nr), nous pouvons calculer le nombre de segments nécessaires ; nous utilisons le symbole Ns pour représenter ce nombre. Donc :
Ns = capacité/Nr
Ainsi, la longueur d'une tranche de bits en bits est Ns.
Probabilité de fausse correspondance
Lorsque la probabilité de fausse correspondance a été introduite, elle a été définie comme le nombre de descripteurs à examiner pour obtenir une fausse correspondance. Une valeur de 1 024 est donc interprétée comme la probabilité d'une fausse correspondance tous les 1 024 descripteurs examinés. L'utilisation de cette mesure n'est pas très utile lors de la configuration d'une base de données Texpress, car la probabilité est liée à la capacité de la table plutôt qu'aux descripteurs examinés lors de la requête. Afin de résoudre ce problème, les probabilités de fausses correspondances utilisées par Texpress sont modifiées pour refléter la probabilité d'une fausse correspondance lors d'une recherche dans le fichier de segments et la probabilité d'une fausse correspondance dans un segment lors d'une recherche dans le fichier de descripteurs d'enregistrements. Pour effectuer ces ajustements, les formules suivantes sont utilisées :
Probabilité d'une fausse correspondance au niveau du segment = 1/(fs * Ns)
Probabilité d'une fausse correspondance de segment = 1/(fr * Nr)
Si nous examinons la première formule, nous constatons que la probabilité d'une fausse correspondance au niveau du segment est passée d'un descripteur sur fs à un sur fs recherches. Cette modification supprime le nombre de descripteurs de segments de l'équation. Ce faisant, fs est maintenant une valeur constante quel que soit le nombre de descripteurs de segments. Une modification similaire a été apportée à la probabilité de fausse correspondance pour les descripteurs d'enregistrements. Le nombre d'enregistrements par segment a été introduit afin que la probabilité soit désormais le nombre de segments examinés avant une fausse correspondance, plutôt que le nombre d'enregistrements.
Nous avons passé beaucoup de temps à examiner les principes fondamentaux du mécanisme d'indexation de Texpress. Il y a cependant une variable qui nécessite une étude plus approfondie, car elle joue un rôle important dans la génération automatique des valeurs de configuration. La variable est le nombre d'atomes indexés par enregistrement (is et ir).
Un atome est un composant de base indexable. Chaque atome correspond à un composant recherchable dans les index Texpress. La définition d’un atome dépend du type de champ de données. La table ci-dessous indique, pour chaque type de données pris en charge, ce qui constitue un atome :
|
float integer |
Une valeur numérique simple constitue un atome. |
|
date |
Chaque valeur de date est constituée de trois composants (année, mois, jour). Chaque composant rempli est un atome. Par exemple, si un champ de date contient |
|
heure |
Comme pour les dates, les valeurs temporelles sont constituées de trois composants (heure, minute, seconde). Chaque composant qui a une valeur est un atome. Par exemple, une valeur temporelle de |
|
latitude |
Les valeurs de latitude et de longitude sont constituées de quatre composants (degré, minute, seconde, direction). Chaque composant ayant une valeur est un atome. Par exemple, une latitude de |
|
chaîne |
Une valeur de chaîne (rarement utilisée dans EMu) est une valeur de texte indexée comme un atome. La valeur des données est débarrassée de toute ponctuation et la chaîne de caractères qui en résulte forme un seul composant. Par exemple, une valeur de chaîne « |
|
text |
Pour les données textuelles, chaque mot unique du texte constitue un atome. Un mot est une séquence de caractères alphabétiques ou numériques délimitée par la ponctuation (la casse des caractères est ignorée). Par exemple, une valeur textuelle « |
Si une colonne peut contenir une liste de valeurs, le nombre d'atomes est la somme des atomes de chaque valeur individuelle, les atomes en double étant supprimés. Ainsi, si vous avez une colonne de nombres entiers qui accepte des valeurs multiples et que les données sont 10, 12, 14 et 12, le nombre d'atomes est de trois (car 12 est en double).
La table ci-dessus reflète ce qu'est un atome pour les types de données standard utilisés par Texpress. Texpress propose toutefois des schémas d'indexation supplémentaires qui offrent des caractéristiques de recherche différentes. La table ci-dessous détaille ce qui constitue un atome pour chacun de ces systèmes d'indexation supplémentaires :
|
Indexation Null |
L'indexation null permet une recherche rapide lorsqu'il s'agit de déterminer si une colonne contient une valeur ou si elle est vide (c'est-à-dire pour les recherches avec les caractères génériques *, !*, + et !+). Il est disponible pour tous les types de données. Il y a un atome par colonne pour toutes les colonnes dont l'indexation null est activée, qu'elles contiennent plusieurs valeurs, une seule valeur ou qu'elles soient vides. |
|
Indexation partielle |
L'indexation partielle permet une recherche rapide lorsque le terme de la recherche spécifie des lettres de début suivies de caractères génériques (par exemple,
Si nous fournissons une indexation partielle pour un et trois caractères, les atomes d'un caractère sont :
et les trois atomes de caractères sont :
Le nombre d'atomes pour l'indexation partielle dans l'exemple ci-dessus est donc de quatre. Pour les colonnes qui contiennent plusieurs valeurs de texte, le nombre d'atomes est la somme des atomes par valeur de texte, les atomes en double étant supprimés. |
|
Indexation lemmatique (Stem indexing) |
L'indexation lemmatique permet de rechercher tous les mots qui ont la même racine. Cela permet aux utilisateurs de trouver un mot indépendamment de sa forme (par exemple, si vous recherchez |
|
Indexation phonétique (Phonetic indexing) |
L'indexation phonétique permet de rechercher des mots sonnant pareil, c'est-à-dire qui contiennent les mêmes groupes de sons (par exemple, |
|
Indexation des phrases |
L'indexation des phrases permet une recherche rapide pour les recherches basées sur des phrases, c'est-à-dire les recherches où les termes de la requête sont placés entre guillemets (par exemple, «
Chacune de ces combinaisons est un atome, mais EMu ne définit qu'un seul bit pour fournir une requête basée sur une phrase, plutôt que les k bits normaux. |
Maintenant que nous savons ce qu'est un atome, nous devons examiner comment Texpress calcule le nombre d'atomes dans un enregistrement.
Lors de l'explication des variables de configuration utilisées pour configurer une table Texpress, le nombre d'atomes par enregistrement (i) n’a pas été révélé. L'exemple de travail a utilisé une valeur de cinq sur la base des données trouvées dans un seul enregistrement. En fait, la détermination d'une valeur pour le nombre de termes d'indexation par enregistrement peut être assez complexe. Il s'avère également que la valeur choisie a un impact important sur la configuration globale du système (ce qui est prévisible puisqu'elle joue un rôle important dans le calcul de b (longueur du descripteur en bits)). Texpress 8.2.01 a introduit des changements dans le système d'indexation permettant de suivre dynamiquement le nombre d'atomes par enregistrement. Grâce à ces modifications, Texpress peut fournir de très bonnes configurations quelle que soit la distribution du nombre d'atomes par enregistrement.
Comment Texpress décide-t-il du nombre d'atomes par enregistrement ? Tout d'abord, nous devons examiner quel est le nombre d'atomes dans un enregistrement pour un enregistrement donné. D'après la section précédente (Qu'est-ce qu'un atome ?), le nombre d'atomes dans un enregistrement donné est composé de trois chiffres :
|
conditions |
Le nombre de termes pour lesquels k bits sont définis lors de la construction du descripteur. La plupart des atomes entrent dans cette catégorie. |
|
extra |
Le nombre d'atomes supplémentaires où deux bits sont définis pour le mot complet. Les atomes supplémentaires résultent de la recherche lemmatique et de la recherche phonétique. |
|
adjacent |
Le nombre d'atomes adjacents où une combinaison de deux mots est indexée ensemble, ce qui fait qu'un bit est défini. |
Prenons un exemple. Si nous avons un enregistrement avec un champ de texte dont l'indexation lemmatique est activée et qu'il contient le texte suivant I like lollies do you?alors la décomposition des atomes est :
|
Type d'index |
Nombre |
Bits définis |
Atomes |
|---|---|---|---|
| conditions | 5 | k | i, like, lollies, do, you |
| extras | 5 | 2 | i, lik, lol, do, you |
| adjacent | 4 | 1 | i-like, like-lollies, lollies-do, do-you |
Afin d'obtenir le nombre d'atomes pour l'enregistrement, nous devons calculer un nombre pondéré d'atomes basé sur le nombre de bits définis. La formule est la suivante :
i = (termes * k + extra * 2 + adjacent * 1)/k
Ainsi, en reprenant notre exemple et en supposant que k=5, le nombre d'atomes pour l'enregistrement test est (5 * 5 + 5 * 2 + 4 * 1) / 5 ou 8 (arrondi au chiffre supérieur). Étant donné que nous avons deux valeurs pour le nombre de bits à définir par terme indexé (ks et kr pour les descripteurs de segment et les descripteurs d'enregistrement respectivement), nous obtenons deux valeurs pondérées pour le nombre d'atomes : une pour le niveau segment (is) et une pour le niveau enregistrement (ir).
Comme vous pouvez l'imaginer, cela peut prendre beaucoup de temps de calculer le nombre d'atomes dans un enregistrement pour chaque enregistrement d'une table. Texpress vous facilite la tâche en stockant les trois chiffres nécessaires pour déterminer i avec chaque descripteur d'enregistrement. Lorsqu'un enregistrement est inséré ou mis à jour, les comptes sont ajustés pour refléter les données stockées dans l'enregistrement. En utilisant texanalyse les atomes pour chaque enregistrement peuvent être visualisés. L'option -r est utilisée pour vider les comptes bruts :
texanalyse -r eparties
Conditions,Extra,Adjacent,RecWeighted,SegWeighted
118,9,14,123,122
126,10,21,132,131
102,3,2,103,103
139,12,39,148,146
130,12,28,137,136
138,15,36,147,145
136,15,36,145,143
…
Les trois premières colonnes de chiffres correspondent au nombre de termes, d'atomes supplémentaires et d'atomes adjacents. Les deux derniers nombres sont le nombre pondéré d'atomes pour le niveau du descripteur d'enregistrement (ir) et le niveau du descripteur de segment (is) respectivement. Ces chiffres constituent l'entrée brute utilisée par Texpress pour déterminer le nombre global d'atomes à utiliser pour la configuration.
Une méthode pour obtenir le nombre d'atomes à utiliser pour la configuration consiste à prendre la moyenne du nombre pondéré d'atomes dans chaque enregistrement. Dans ce cas, un certain pourcentage d'enregistrements serait inférieur à la valeur moyenne et le reste supérieur. Pour les enregistrements avec la valeur moyenne, la densité de bits des descripteurs générés sera d (25 % par défaut). Pour les enregistrements dont le nombre d'atomes est inférieur à la moyenne, la densité de bits sera inférieure à d, et pour ceux qui sont supérieurs à la moyenne, elle sera supérieure à d. D'après nos premiers calculs :
k = log(f) / log(100 / d)
Nous devons maintenir la densité de bits (d) à environ 25 %, étant donné que k est fixe, sinon la probabilité de fausse correspondance diminue et les fausses correspondances sont plus probables. Nous devons veiller à ce que la grande majorité des enregistrements aient une densité de bits de 25 % ou moins. Pour ce faire, nous ne pouvons pas utiliser le nombre moyen d'atomes par enregistrement, nous devons plutôt choisir une valeur plus élevée.
Si nous calculons le nombre moyen d'atomes par enregistrement et que nous connaissons l'écart-type, nous pouvons utiliser l'analyse statistique pour déterminer une valeur pour le nombre d'atomes qui garantit que la plupart des enregistrements soient inférieurs à cette valeur (et donc que la densité de bits est inférieure à 25 %). Si le nombre d'atomes dans chaque enregistrement suit une distribution normale, ce qui est généralement le cas lorsque les données proviennent d'une seule source, l'analyse montre que 95,4 % des enregistrements auront une valeur du nombre d'atomes inférieure à la moyenne plus deux fois l'écart-type, et que 99,7 % des enregistrements auront une valeur du nombre d'atomes inférieure à la moyenne plus trois fois l'écart-type. Le calcul de l'écart-type du nombre d'atomes dans chaque enregistrement pourrait prendre un certain temps. Heureusement, texanalyse peut être utilisé pour déterminer cette valeur. Si texanalyse est exécuté sans options, le résultat suivant est affiché :
texanalyse eparties
Analyse des atomes indexés par enregistrement
====================================
+---------+---------+---------+
| Atomes |Records|Records|Records|
| | (Rec) | (Seg) |
+---------+---------+---------+
| 93 | 0 | 1 |
| 94 | 1 | 0 |
| 95 | 0 | 3 |
| 96 | 3 | 2 |
| 97 | 2 | 0 |
| 98 | 3 | 3 |
| 99 | 8 | 8 |
| 100 | 0 | 2 |
| 101 | 3 | 1 |
| 102 | 1 | 1 |
| 103 | 13 | 15 |
| 104 | 2198 | 2223 |
| 105 | 966 | 976 |
| 106 | 43 | 290 |
| 107 | 288 | 94 |
…
| 397 | 0 | 0 |
| 398 | 1 | 0 |
+---------+---------+---------+
Analyse au niveau de l’enregistrement
=====================
Nombre total d’enregistrements : 50046
Nombre total de termes indexés : 6169873
Nombre moyen de termes indexés : 123,3
Écart-type : 18,5
Enregistrements <= moyenne : 32726 (65,4<= 123,3)
Enregistrements <= moyenne + 1 * écart-type : 46156 (92,2<= 141,8)
Enregistrements <= moyenne + 2 * écart-type : 48310 (96,5<= 160,4)
Enregistrements <= moyenne + 3 * écart-type : 49114 (98,1<= 178,9)
Enregistrements <= moyenne + 4 * écart-type : 49456 (98,8<= 197,4)
Enregistrements <= moyenne + 5 * écart-type : 49638 (99,2<= 215,9)
Enregistrements <= moyenne + 6 * écart-type : 49732 (99,4<= 234,5)
Enregistrements <= moyenne + 7 * écart-type : 49838 (99,6<= 253,0)
Enregistrements <= moyenne + 8 * écart-type : 49938 (99,8<= 271,5)
Enregistrements <= moyenne + 9 * écart-type : 49990 (99,9<= 290,1)
Enregistrements <= moyenne + 10 * écart-type : 50014 (99,9<= 308,6)
Enregistrements <= moyenne + 11 * écart-type : 50027 (100,0<= 327,1)
Enregistrements <= moyenne + 12 * écart-type : 50036 (100,0<= 345,7)
Enregistrements <= moyenne + 13 * écart-type : 50038 (100,0<= 364,2)
Enregistrements <= moyenne + 14 * écart-type : 50044 (100,0<= 382,7)
Enregistrements <= moyenne + 15 * écart-type : 50046 (100,0<= 401,3)
Analyse au niveau des segments
======================
Nombre total d’enregistrements : 50046
Nombre total de termes indexés : 6112301
Nombre moyen de termes indexés : 122,1
Écart-type : 17,8
Enregistrements <= moyenne : 32744 (65,4<= 122,1)
Enregistrements <= moyenne + 1 * écart-type : 46163 (92,2<= 139,9)
Enregistrements <= moyenne + 2 * écart-type : 48306 (96,5<= 157,7)
Enregistrements <= moyenne + 3 * écart-type : 49126 (98,2<= 175,5)
Enregistrements <= moyenne + 4 * écart-type : 49459 (98,8<= 193,2)
Enregistrements <= moyenne + 5 * écart-type : 49645 (99,2<= 211,0)
Enregistrements <= moyenne + 6 * écart-type : 49728 (99,4<= 228,8)
Enregistrements <= moyenne + 7 * écart-type : 49832 (99,6<= 246,6)
Enregistrements <= moyenne + 8 * écart-type : 49938 (99,8<= 264,4)
Enregistrements <= moyenne + 9 * écart-type : 49989 (99,9<= 282,1)
Enregistrements <= moyenne + 10 * écart-type : 50014 (99,9<= 299,9)
Enregistrements <= moyenne + 11 * écart-type : 50027 (100,0<= 317,7)
Enregistrements <= moyenne + 12 * écart-type : 50036 (100,0<= 335,5)
Enregistrements <= moyenne + 13 * écart-type : 50038 (100,0<= 353,2)
Enregistrements <= moyenne + 14 * écart-type : 50044 (100,0<= 371,0)
Enregistrements <= moyenne + 15 * écart-type : 50046 (100,0<= 388,8)
La table sous le titre Analyse des atomes indexés par enregistrement montre pour un nombre donné d'atomes (dans la colonne Atomes) combien d'enregistrements ont ce nombre d'atomes au niveau de l'enregistrement (Enregistrements (Enr)) et au niveau du segment (Enregistrements (Seg)). L’Analyse au niveau de l'enregistrement et l'Analyse au niveau du segment indiquent le nombre moyen d'atomes et l'écart-type pour chaque niveau. La table en dessous de l'écart-type indique le nombre d'enregistrements inférieurs à la moyenne plus un multiple de l'écart-type. Le premier nombre entre parenthèses est le pourcentage d'enregistrements inférieurs à la valeur et le nombre après le signe égal est le nombre d'atomes. Par exemple, si vous prenez la ligne :
Records <= average + 3 * standard deviation: 49126 (98.2<= 175.5)cela indique que 49 126 enregistrements sont inférieurs à la moyenne plus trois fois l'écart-type, ce qui représente 98,2 % des enregistrements. Le nombre d'atomes représenté par la moyenne plus trois fois l'écart-type est de 175,5. En utilisant cette table, il est possible de déterminer quelles seraient les bonnes valeurs pour is et ir. Souvenez-vous, nous voulons que la plupart des enregistrements soient inférieurs à la valeur sélectionnée, dans la plupart des cas au-dessus de 98 %. En utilisant ceci comme guide, pour la sortie ci-dessus, une valeur appropriée pour ir serait 180 (178,9 arrondi au nombre supérieur) et pour is 175 (175,5 arrondi au nombre inférieur). Même si ces valeurs semblent bonnes à première vue, il convient de considérer également les extrêmes supérieurs. Pour l'analyse au niveau des enregistrements, le nombre maximum d'atomes dans un enregistrement est de 398. Si nous utilisons une valeur de 180 pour le nombre d'atomes au niveau de l'enregistrement, cela signifie que l'enregistrement avec le nombre maximum d'atomes fixe 2,2 fois le nombre de bits qu'un enregistrement avec 180 atomes. Si nous appliquons cela à la densité de bits, cela correspond à 55 % (25 % * 2,2). Si nous utilisons la valeur 5 pour k (cinq bits par atome), la probabilité de fausse correspondance pour l'enregistrement comportant 398 atomes est la suivante :
(55/100)5 ≈ 0.05 or 1/20 Ainsi, l'enregistrement avec 398 atomes a une probabilité de fausse correspondance de 1/20 au lieu du 1/1024 requis. En général, il s'agit d'une valeur acceptable, à condition qu'il n'y ait pas beaucoup d'enregistrements avec une probabilité aussi élevée. Toutefois, si la densité de bits est supérieure à 75 % pour l'enregistrement comportant le nombre maximal d'atomes, il peut être intéressant d'augmenter la valeur de i de manière à diminuer la densité (en faisant en sorte que i représente environ un tiers de la valeur du nombre maximal d'atomes). En général, cela n'est nécessaire que dans des cas extrêmes et ne se produit que lorsqu'un grand nombre de sources de données sont chargées dans une table.
L'idée d'ajouter un certain nombre d'écarts types au nombre moyen d'atomes nous fournit notre dernière variable :
|
v |
Le nombre d'écarts types à ajouter au nombre moyen d'atomes par enregistrement pour déterminer la valeur de i, communément appelé la variance. Puisque nous avons un segment et une valeur de niveau d'enregistrement pour i, nous avons également un segment et une valeur de niveau d'enregistrement pour v. La valeur par défaut pour le niveau du segment est 2,0, et pour le niveau de l'enregistrement 3,0. C'est-à-dire que nous ajoutons deux fois l'écart-type pour calculer la valeur de is et trois fois l'écart-type pour calculer ir. |
Il peut être opportun à ce stade de résumer les variables utilisées dans le cadre de la configuration d'une base de données Texpress. Comme Texpress utilise un schéma à deux niveaux, il y a deux ensembles de variables, un pour le niveau du segment et un pour le niveau de l'enregistrement. Les variables portant l'indice r s'appliquent aux descripteurs d'enregistrements, tandis que celles portant l'indice s sont utilisées pour les descripteurs de segments :
|
Variable |
Description |
Valeur par défaut |
|---|---|---|
| Ns | Nombre de descripteurs de segments | Calculé à partir de la capacité |
| Nr | Nombre de descripteurs d'enregistrement par segment | Calculé avec un minimum de 10 |
| kr | Bits à définir par terme dans le descripteur d'enregistrement | Calculé |
| ks | Bits à définir par terme dans le descripteur de segment | Calculé |
| br | Longueur en bits d'un descripteur d'enregistrement | Calculé |
| bs | Longueur en bits d'un descripteur de segment | Calculé |
| fr | Probabilité de fausse correspondance pour les descripteurs d'enregistrements | 1024 |
| fs | Probabilité de fausse correspondance pour les descripteurs de segments | 4 |
| dr | Densité de bits des descripteurs d'enregistrement | 25 % |
| ds | Densité de bits des descripteurs de segments | 25 % |
| ir | Termes indexés par descripteur d'enregistrement | Calculé à partir des données |
| is | Termes indexés par descripteur de segment | Calculé à partir des données |
| vr | Nombre d'écarts-types à ajouter à la moyenne au niveau de l'enregistrement | 3.0 |
| vs | Nombre d'écarts-types à ajouter à la moyenne au niveau du segment | 2.0 |
| taille du bloc | Taille du système de fichiers en lecture/écriture en octets | 4096 |
Texpress2 dispose d'un certain nombre d'outils qui fournissent des informations détaillées sur le mécanisme d'indexation. Trois programmes sont proposés, chacun se concentrant sur un aspect de la configuration du système :
- texanalyse fournit des informations sur le nombre d'atomes par enregistrement.
- texdensity affiche la densité de bits réelle pour chaque segment et descripteur d'enregistrement.
- texconf génère des valeurs pour les variables de configuration calculées (k, b, Nr et Ns).
L'outil texanalyse permet d'obtenir des informations sur le nombre d'atomes par enregistrement. Il prend en charge à la fois le niveau de l'enregistrement et le niveau du segment. L'utilisation principale de texanalyse est de vérifier que la valeur utilisée pour le nombre d'atomes par enregistrement (i) est appropriée : en particulier, il s'agit de vérifier que les enregistrements avec le nombre maximum d'atomes par enregistrement sont dans une plage acceptable de i. Nous définissons l'acceptable comme étant compris dans le triple de la valeur de i lorsqu'une densité de bits (d) de 25 % est utilisée. Il est également instructif d'utiliser texanalyse pour produire les données brutes qui peuvent être transmises à des tableurs pour analyse. Le message d'utilisation est :
Utilisation : texanalyse [-R] [-V] [-c|-r] [-s] dbname
Les options sont :
-c imprimer l’analyse au format CSV
-r imprimer les données brutes au format CSV
-s supprimer les lignes vides
Si les données atomiques brutes par enregistrement sont requises, l'option -r est utilisée :
texanalyse -r eparties
Conditions,Extra,Adjacent,RecWeighted,SegWeighted
118,9,14,123,122
126,10,21,132,131
102,3,2,103,103
139,12,39,148,146
…
La sortie est au format CSV (valeurs séparées par des virgules) pour être chargée dans un tableur ou une base de données. Les données contiennent le nombre d'atomes du terme, celui d'atomes supplémentaires et d'atomes adjacents pour chaque enregistrement de la table. Le nombre pondéré d'atomes au niveau de l'enregistrement et du segment est également indiqué.
Il est également possible d'exporter au format CSV le nombre d'enregistrements, tant au niveau des enregistrements que des segments, qui ont un nombre donné d'atomes :
texanalyse -c eparties
Atomes,RecRecords,SegRecords
101,3,1
102,1,1
103,13,15
104,2198,2223
105,966,976
106,43,290
107,288,94
108,93,19
109,536,527
110,15,13
111,6,20
…
Les résultats peuvent être chargés dans des tableurs pour être analysés. Le graphique ci-dessous montre le nombre d'enregistrements pour chaque nombre d'atomes de la sortie ci-dessus au niveau des enregistrements :
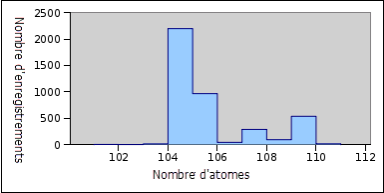
La production d'un graphique du nombre d'enregistrements avec chaque nombre d'atomes fournit un mécanisme utile pour déterminer dans quelle mesure la distribution du nombre d'atomes dans un enregistrement est proche d'une distribution normale. En particulier, il peut être utilisé pour voir si le chargement de sources de données distinctes a donné lieu à la superposition d'un certain nombre de distributions normales (une par source de données). Le graphique au début de cet article montre clairement qu'au moins trois sources de données distinctes ont été chargées dans la table Personnes / Organisations.
L'utilisation finale de texanalyse est de produire un résumé détaillant le nombre moyen d'atomes par enregistrement et l'écart-type. Une liste de la moyenne plus un nombre entier d'écarts-types est également indiquée :
elocations texanalyse
Analyse des atomes indexés par enregistrement
====================================
+---------+---------+---------+
| Atomes |Records|Records|Records|
| | (Rec) | (Seg) |
+---------+---------+---------+
| 49 | 17 | 17 |
| 50 | 0 | 0 |
…
| 106 | 0 | 1 |
+---------+---------+---------+
Analyse au niveau de l’enregistrement
=====================
Nombre total d’enregistrements : 1419
Nombre total de termes indexés : 90309
Nombre moyen de termes indexés : 63,6
Ecart-type : 9,4
Enregistrements <= moyenne : 1170 (82,5<= 63,6)
Enregistrements <= moyenne + 1 * écart-type : 1244 (87,7<= 73,1)
Enregistrements <= moyenne + 2 * écart-type : 1313 (92,5<= 82,5)
Enregistrements <= moyenne + 3 * écart-type : 1323 (93,2<= 91,9)
Enregistrements <= moyenne + 4 * écart-type : 1418 (99,9<= 101,4)
Enregistrements <= moyenne + 5 * écart-type : 1419 (100,0<= 110,8)
Analyse au niveau des segments
======================
Nombre total d’enregistrements : 1419
Nombre total de termes indexés : 91805
Nombre moyen de termes indexés : 64,7
Écart-type : 9,8
Enregistrements <= moyenne : 1167 (82,2<= 64,7)
Enregistrements <= moyenne + 1 * écart-type : 1243 (87,6<= 74,5)
Enregistrements <= moyenne + 2 * écart-type : 1311 (92,4<= 84,3)
Enregistrements <= moyenne + 3 * écart-type : 1323 (93,2<= 94,1)
Enregistrements <= moyenne + 4 * écart-type : 1417 (99,9<= 103,9)
Enregistrements <= moyenne + 5 * écart-type : 1419 (100,0<= 113,7)
Les tables d'analyse à la fin peuvent être utilisées pour déterminer si le nombre calculé d'atomes par enregistrement est approprié. La valeur calculée du niveau d'enregistrement est la moyenne plus trois fois l'écart-type et la valeur du segment est la moyenne plus deux fois l'écart-type. La vérification standard consiste à s'assurer que le nombre maximal d'atomes est inférieur à trois fois la valeur choisie pour i (en supposant une densité de bits (d) de 25 %).
Afin de tester l'efficacité d'une configuration, il est utile de pouvoir déterminer la densité de bits pour tous les descripteurs de segments et d'enregistrements. L'utilitaire texdensity fournit cette fonctionnalité. Le message d'utilisation est :
Utilisation : texdensity [-R] [-V] [[-cr|-cs] | [-dr|-ds]] [-s] [-nrn -nsn] dbname
Les options sont :
-cr imprime la densité du descripteur d'enregistrement au format CVS
-cs imprime la densité du descripteur de segment au format CVS
-dr imprime la densité du descripteur d'enregistrement
-dr imprime la densité du descripteur de segment
-s supprime les valeurs vides
-nrn scan n descripteurs d’enregistrements
-nsn scan n descripteurs de segments
Si une analyse de la densité de bits est nécessaire, les options -cr ou -cs peuvent être utilisées pour sortir au format CSV le nombre de bits définis et la densité de bits par enregistrement ou descripteur de segment respectivement :
texdensity -cr elocations
Index,Bits,Total,Densité
0,424,2384,17.79
1,405,2384,16.99
2,404,2384,16.95
3,438,2384,18.37
…
La colonne Index est l'index du descripteur d'enregistrement (ou du descripteur de segment si -cs est utilisé). Viennent ensuite le nombre de bits définis, puis le nombre total de bits qui pourraient être définis et enfin la densité de bits en pourcentage. En général, la densité de bits doit être inférieure à la valeur par défaut de 25 %.
Il est également possible d'obtenir la densité de bits moyenne, l'écart-type et la densité de bits maximale :
texdensity -ds elocations
Analyse des descripteurs de segments
===========================
Descripteur Bits définis Total des bits Densité
+----------+----------+----------+----------+
| 0 | 1193 | 17280 | 6.90 |
| 1 | 1164 | 17280 | 6.74 |
| 2 | 1007 | 17280 | 5.83 |
| 3 | 971 | 17280 | 5.62 |
…
| 135 | 0 | 17280 | 0.00 |
+----------+----------+----------+----------+
Nombre de descripteurs : 119
Densité moyenne : 4,42
Écart-type :1,10
Densité maximale : 10,39
La sortie ci-dessus montre le résumé pour les descripteurs de segment de la table elocations. Comme la densité maximale de 10,39 est bien inférieure à la densité requise de 25 %, cela indique que la valeur du nombre d'atomes par enregistrement peut être abaissée. Le nombre calculé d'atomes par enregistrement au niveau du segment était de 83. Si nous diminuons proportionnellement le nombre d'atomes par enregistrement (83 * 10.39 / 25), le nombre d'atomes à utiliser est de 34. Après avoir reconfiguré le nombre d'atomes par enregistrement au niveau du segment à 34, on trouve le résumé de densité suivant :
Nombre de descripteurs : 119
Densité moyenne : 10,45
Écart-type : 2,44
Densité maximale : 23,37
Sur la base de ce résultat, le chiffre pourrait être encore abaissé, car la densité de bits moyenne est de 10,45 et si nous ajoutons trois fois l'écart-type, nous obtenons 17,77 (10.45 + 3 * 2.44), ce qui est encore bien inférieur à 25 %. La raison pour laquelle les densités de bits des descripteurs de segments sont généralement plus faibles que celles des descripteurs d'enregistrements est due à la répétition des atomes dans tous les enregistrements qui composent le descripteur de segment. En particulier, il existe un certain nombre de champs dans EMu qui contiennent la même valeur pour tous les enregistrements d'un segment (par exemple, Statut de l'enregistrement, Publié sur l'Internet, Publié sur l'Intranet, Sécurité au niveau de l'enregistrement, etc.) Puisque chaque enregistrement du segment a la même valeur dans ces champs, nous ne devrions compter l'atome qu'une seule fois, mais Texpress n'a pas de mécanisme disponible pour suivre le nombre d'atomes répétés dans un segment, donc on suppose le pire des scénarios où aucun atome n'est répété. En général, cela se traduit par des fichiers de descripteurs de segments plus volumineux qu'ils ne devraient l'être. Outre le fait qu'il utilise plus d'espace disque, le mécanisme de requête n'est pas affecté de manière flagrante puisque des tranches de bits sont lues plutôt que des descripteurs de segment complets. Il est possible d'ajuster le nombre d'atomes par enregistrement au niveau du segment, ce qui permet dans certains cas de réaliser des économies substantielles d'espace disque.
La section suivante, consacrée à la définition des paramètres de configuration, détaille la manière dont ces paramètres sont définis.
L'utilitaire texconf est un programme frontal de l'outil de configuration de Texpress. En utilisant texconf, il est possible de modifier n'importe quelle variable de configuration et de voir l'effet qu'elle a sur la configuration finale (c'est-à-dire les valeurs de Nr, Ns, br, bs, kr et ks). Le message d'utilisation est :
Utiliser : texconf [-R] [-V] [-bn] [-cn] [-drn] [-dsn] [-frn] [-fsn] [-mn] [-irn -isn -nrn -nsn -vrn -vsn] dbname
Les options sont :
-bn taille de bloc du système de fichiers de n octets
-cn capacité de n enregistrements
-drn densité de bits du descripteur d'enregistrement de n
-dsn densité de bits du descripteur de segment de n
-frn descripteur d'enregistrement probabilité de fausse correspondance de n
-fsn probabilité de fausse correspondance du descripteur de segment de n
-mn nombre minimum d'enregistrements par segment de n
-irn descripteur d'enregistrement termes indexés par enregistrement de n
-est termes indexés du descripteur de segment par enregistrement de n
-nrn scanner n enregistrements pour déterminer la valeur de -ir
-nrn scanner n enregistrements pour déterminer la valeur de -is
-vrn augmenter la valeur de -ir de n écarts-types
-vsn augmente la valeur de -is de n écarts-types
Un examen attentif des options montre que la plupart correspondent aux variables abordées dans cet article. En utilisant les options, vous pouvez tester l'effet de la modification des variables. Exécuter texconf sans aucune option générera une configuration basée sur les valeurs par défaut en utilisant la capacité actuelle de la base de données :
elocations de texconf
Configuration de l'index
===================
Capacité de la base de données (dans les enregistrements) : 1632
Nombre de segments (Ns) : 136
Nombre d’enregistrements par segment (Nr) : 12
Mots par descripteur de segments : 540
Mots par descripteur d’enregistrements : 79
Bits définis par terme indexé (segment) : 5
Bits définis par terme indexé (enregistrement) : 7
Configuration du descripteur d'enregistrement
===============================
Documents scannés pour déterminer les termes indexés : 1419
Nombre moyen de termes indexés : 63,6
Écart-type des termes indexés : 9,4
Écarts types pour augmenter la moyenne : 3,0
Nombre attendu de termes indexés : 92
Probabilité de fausse correspondance (enregistrement) : 0,000081 [1 / (1024 * Nr)]
Longueur de balise (en bits) de descripteur d’enregistrement : 144
Bits définis par terme supplémentaire : 2
Bits définis par terme adjacent : 1
Configuration du descripteur de segment
================================
Segments analysés pour déterminer les termes indexés : 118
Nombre moyen de termes indexés : 776,0
Écart-type des termes indexés : 108,8
Écarts types pour augmenter la moyenne : 2,0
Nombre attendu de termes indexés : 994
Nombre moyen de termes indexés par enregistrement : 64,7
Écart-type des termes par enregistrement : 9,1
Nombre attendu de termes indexés par enregistrement : 82
Probabilité de fausse correspondance : 0,001838 [1 / (4 * Ns)]
Bits définis par terme supplémentaire : 2
Bits définis par terme adjacent : 1
Tailles d'index
===========
Taille de segment : 4096
Taille du fichier descripteur de segment : 286,88 K
Taille du fichier descripteur d’enregistrement : 544,00 K
Pourcentage de fichier descripteur d’enregistrement perdu : 1,56 %
Total du surcoût d’index : 830,88 K
La sortie est divisée en quatre secteurs. Le premier (Configuration d’index) imprime les valeurs de configuration générées. Ces valeurs peuvent être saisies à l'écran de configuration de Texpress. Le deuxième (Configuration du descripteur d'enregistrement) détaille les paramètres utilisés lors du calcul de la configuration du descripteur d'enregistrement. Le troisième (Configuration du descripteur de segment) indique les valeurs utilisées lors du calcul de la configuration du descripteur de segment. Le dernier (Tailles d’index) indique la taille des fichiers d'index requis pour la configuration générée.
La table ci-dessous indique où se trouve chacune des variables de configuration :
|
Variable |
Nom dans texconf |
|---|---|
| Ns | Nombre de segments (Ns) |
| Nr | Nombre d’enregistrements par segment (Nr) |
| bs | Mots par descripteur de segments (multiplier par 32) |
| br | Mots par descripteur d'enregistrement (multiplier par 32) |
| ks | Bits définis par terme indexé (segment) |
| kr | Bits définis par terme indexé (enregistrement) |
| is | Nombre attendu de termes indexés [Configuration des descripteurs de segment] |
| ir | Nombre attendu de termes indexés [Configuration des descripteurs d’enregistrements] |
| fs | Probabilité de fausse correspondance [Configuration du descripteur de segment] |
| fr | Probabilité de fausse correspondance [Configuration du descripteur d’enregistrement] |
| vs | Écarts-types pour augmenter la moyenne [Descripteur de segment Configuration] |
| vr | Écarts-types pour augmenter la moyenne [Descripteur d'enregistrement Configuration] |
Disons qu'après une certaine analyse, nous décidons que le nombre moyen d'atomes par enregistrement au niveau du segment devrait être de 34 au lieu de 82. On peut exécuter :
texconf -is34 elocations
Configuration de l'index
===================
Capacité de la base de données (dans les enregistrements) : 1632
Nombre de segments (Ns) : 136
Nombre d’enregistrements par segment (Nr) : 12
Mots par descripteur de segments : 222
Mots par descripteur d’enregistrements : 79
Bits définis par terme indexé (segment) : 5
Bits définis par terme indexé (enregistrement) : 7
…
Tailles d'index
===========
Taille de segment : 4096
Taille du fichier du descripteur de segment : 117,94 K
Taille du fichier descripteur d’enregistrement : 544,00 K
Pourcentage de fichier descripteur d’enregistrement perdu : 1,56 %
Total du surcoût d’index : 661,94 K
Remarquez comment la valeur du descripteur Mots par descripteur de segment a diminué pour refléter le nombre inférieur d'atomes par enregistrement. La taille du fichier du Descripteur de segment a également diminué. En utilisant texconf vous pouvez déterminer l'impact sur la taille des fichiers d'index lorsque les variables de configuration sont ajustées.
La dernière partie de ce document traite du réglage des variables de configuration pour chaque base de données afin que les configurations futures utilisent ces valeurs.
Ces informations constituent l'étape 7 de Comment optimiser Texpress.

