Lors de la recherche de vos données EMu, il est possible de :
- recherche d'une expression exacte (Recherche d'expression)
- trouver des variantes d'un terme de recherche (Lemmatisation)
- repérer les termes qui ressemblent au terme de recherche (Recherche phonétique)
- effectuer une recherche sensible à la casse
- effectuer des recherches sur des fourchettes de dates, d'heure et autres valeurs numériques, y compris les latitude / longitude (Recherche de gamme)
- repérer les fiches où deux termes apparaissent proches l'un de l'autre dans un corps de texte (Recherche de proximité).
- utiliser des caractères de remplacement (Correspondance de motifs)
Comme nous allons le voir, ces différents types de requête peuvent être combinés de manière très efficace.
EMu est compatible avec Unicode, ce qui signifie qu'il est possible, entre autres, de rechercher des signes de ponctuation et d'autres caractères spéciaux soit en tant que caractères individuels (? ) ou dans le cadre d'une chaîne plus complexe (fred@global.com).
Comme nous le décrivons ci-dessous, certains caractères peuvent avoir une signification particulière lors d'une requête dans EMu. Un point d'interrogation peut être utilisé à la place d'un seul caractère dans un terme de la requête ; par exemple, si nous ne sommes pas sûrs que l'orthographe ise ou ize a été utilisée (par exemple organise/organize), nous pouvons utiliser un point d'interrogation ? à la place du s/z, c'est-à-dire organi?e pour rechercher les deux mots.
Cependant, comme il est possible de rechercher un point d'interrogation en tant que tel, nous devons indiquer à EMu quand nous voulons que sa signification spéciale s'applique.
L'application de la signification particulière d'un caractère s’effectue en l'échappant , ce qui peut être fait avec une barre oblique inverse \.
Par exemple :
- Une requête de organi?e tentera de localiser les huit caractères organi?e.
- Une requête de organi\?e tire parti du caractère générique du point d'interrogation et permet de localiser à la fois organise et organize.
Dans cette section, nous décrivons en détail comment effectuer des recherches dans EMu. Le Unicode Cheat Sheet fournit un guide de référence rapide sur la façon dont les caractères spéciaux sont spécifiés dans une requête :

AND, OR, NOT (connus sous le nom d'opérateurs booléens) peuvent être utilisés pour cibler une requête et obtenir des résultats plus précis. Dans les illustrations ci-dessous, la zone verte (claire) indique les types d'enregistrements qui résulteront d'une requête utilisant chaque opérateur :
|
|
Une requête pour rock AND roll donnera tous les enregistrements contenant les deux mots dans le champ de requête. Elle trouvera des articles sur la musique rock and roll, par exemple. Elle peut également trouver des enregistrements qui contiennent les deux mots dans un contexte différent, comme As hard as he tried, he couldn't roll the rock away from the cave entrance. Elle ne retournera pas les enregistrements dans lesquels rock apparaît sans roll (et vice versa). Conseil : Si vous trouvez trop d'enregistrements sur votre sujet, ajoutez un autre terme de recherche avec l'opérateur ET. |
|
|
Une recherche portant sur rock OR roll donnera tous les enregistrements contenant l'un ou l'autre de ces mots dans le champ de requête. Si un enregistrement contient ces deux termes, il sera trouvé par la recherche, mais il importe seulement que l'un des mots soit trouvé. Conseil : Si vous trouvez quelques enregistrements sur votre sujet, ajoutez un autre terme de recherche avec l'opérateur OU. |
|
|
Une requête de rock NOT roll renverra les enregistrements contenant rock dans le champ de requête, mais pas si le champ de requête comprend également roll. Tout enregistrement qui inclut roll dans le champ de requête ne sera pas retourné. Conseil : Utilisez l'opérateur NOT pour éliminer les enregistrements qui comprennent un terme. |
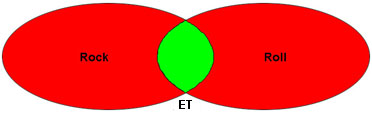
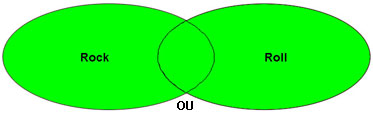
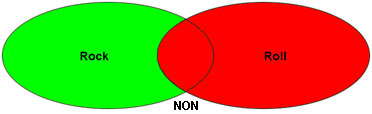
ET et NON réduisent généralement le nombre d'enregistrements trouvés par une recherche et l'opérateur OU augmente le nombre d'enregistrements trouvés.
Si deux termes ou plus sont entrés sur la même ligne d'un champ, l'opérateur booléen ET s'applique (vous n'incluez pas le mot ET) :

Dans cet exemple, les enregistrements contenant les deux mots rock et roll n'importe où n'importe quel ordre, dans le champ Notes seront trouvés.
Conseil : Vous n'êtes pas limité à deux termes de recherche dans une requête avec ET, c.-à-d. vous pourriez entrer rock roll musique et tous ces trois termes devront être présents dans le champ Notes.
Si deux termes ou plus sont entrés sur deux lignes différentes d'un champ, l'opérateur booléen OU s'applique (vous n'incluez pas le mot OU) :

Un enregistrement sera renvoyé s'il contient au moins un des mots, rock ou roll dans cet exemple.
Conseil : Vous n'êtes pas limité à deux termes de requête dans une recherche OR ; il suffit d'ajouter un terme de requête à une autre ligne.
NOT est spécifié en plaçant un point d'exclamation ! avant un terme de requête. L'opérateur NOT exclut les enregistrements qui contiennent le terme suivant dans le champ de requête.
| Requête NOT | Description |
|---|---|
|
|
Les enregistrements qui contiennent le mot rock dans le champ de requête ne seront pas retournés par cette requête. |
\!rock roll
|
Cette requête renverra les enregistrements qui contiennent roll dans le champ de recherche, mais seulement si rock n'apparaît pas aussi dans le champ :
Les enregistrements contenant sausage roll dans le champ de requête seront retournés ; les enregistrements contenant rock and roll dans le champ de requête ne seront pas retournés. |

L'opérateur NOT peut être appliqué à n'importe lequel des autres opérateurs de requête.
| Requête NOT | Description |
|---|---|
| \!\^Inconnu\$ |
Retournez les enregistrements qui contiennent tout autre chose que le mot unique Inconnu (voir Correspondance de motifs). |
| \!\"Non applicable\" |
Retourner les enregistrements qui ne contiennent pas la phrase Non applicable (voir Requête par phrase). |
\"\==Sacré \==Cœur\" \!Paris
|
Retourner les enregistrements contenant la phrase Sacré Cœur avec la signification des majuscules et des diacritiques, mais pas si le champ recherché comprend également Paris (voir Casse et diacritiques). |
NOT et NULL (un champ vide)
Il est important de savoir qu'une requête NOT ne renverra pas un enregistrement où le champ de requête est vide (n'a pas de valeur), même si logiquement un champ vide ne contient pas le terme exclu :
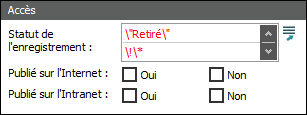
Par exemple, les enregistrements peuvent avoir un Statut de l'enregistrement de Retiré ou Actif. Lorsque chaque enregistrement a une valeur dans le champ Statut de l'enregistrement, une requête d'enregistrements pour lesquels Statut de l'enregistrement est NOT Retiré renverra tous les enregistrements pour lesquels Statut de l'enregistrement est Actif. Toutefois, si un enregistrement n'a aucune valeur dans le champ Statut de l'enregistrement (il est vide), il ne sera pas renvoyé par cette requête.
L'explication technique est qu'il n'est possible de faire correspondre une valeur NULL (un champ vide) qu'avec les opérateurs IS NULL ou IS NOT NULL.
La solution consiste à combiner une recherche NOT avec une requête NULL. Cette opération permet de localiser tous les enregistrements dont le champ n'a pas une valeur particulière, y compris ceux dont le champ est vide.
Ainsi, pour localiser tous les enregistrements dont le champ Statut de l'enregistrement ne contient pas Retiré (tous les enregistrements dont le champ Statut de l'enregistrement contient Actif ainsi que tous les enregistrements dont le champ Champ ne contient aucune valeur), effectuez la recherche OR suivante :
| OU | Description |
|---|---|
|
\!Retiré OU
|
Comme nous l'avons vu dans le document Correspondance de motif : utilisation de caractères génériques, Cette requête donnera tous les enregistrements pour lesquels le champ Tous les enregistrements ne comprend pas Retiré OR est vide. |
De nombreux champs dans EMu sont des champs de texte : noms, adresses, titres, notes. Les requêtes de texte suivantes peuvent être effectuées :
Une phrase est un ou plusieurs mots adjacents les uns aux autres, par exemple : systèmes d'entreprise. Dans une requête par Phrase, les guillemets sont utilisés pour définir l'expression.
Une requête par phrase renvoie les enregistrements qui contiennent les termes recherchés dans l'ordre dans lequel ils apparaissent entre les guillemets :
| Locution |
Résultats de recherche |
|---|---|
|
\"système d'entreprise\" |
Les documents contenant la phrase systèmes d'entreprise seront renvoyés. Une requête par Phrase est plus précise qu'une requête booléenne AND dans laquelle les mots peuvent apparaître n'importe où et dans n'importe quel ordre dans le champ de recherche. Par exemple, une requête AND pour systèmes entreprise renverrait un enregistrement contenant la phrase « L'entreprise a de nombreux systèmes ». Notre exemple de requête par phrase ne renverrait pas cet enregistrement. |
|
|
La requête d'une phrase n'est pas sensible à la casse ou aux diacritiques. Par exemple, dans le premier exemple, les enregistrements avec systèmes d'entreprise, Systèmes d'entreprise ou Systèmes d'Entreprise seront retournés. Et dans cet exemple, les enregistrements contenant la phrase Sacré-Cœur seraient retournés. Conseil : Voir Sensibilité à la casse et aux diacritiques ci-dessous pour plus de détails sur la manière de rendre la requête d'une phrase sensible à la casse. |
Avec la lemmatisation, il est possible de trouver des enregistrements qui contiennent des variations / dérivés d'un terme de requête (par exemple, pluriel, adjectif, conjugaison, etc.).
La lemmatisation est spécifiée en plaçant un ~ (tilde) directement devant le terme recherché :
| Lemmatisation |
Résultats de recherche |
|---|---|
|
\~system |
système, systèmes, systématique, systématiques, systématiquement, systématiser, systémique |
|
\~enregistr |
enregistrer, enregistre, enregistrez, enregistrement, enregistrements |
|
\~blanc |
blancs, blanche, blanches, blanchir, blanchissement, blanchisseuse, blanchisserie |
Une requête phonétique renvoie les enregistrements qui contiennent des termes dont la consonance ressemble à celle du terme recherché. Une requête phonétique utilise le symbole @ :
| Phonétique |
Résultats de recherche |
|---|---|
|
\@pore |
pores, port, ports, porc, porcs |
|
\@noir |
noirs, noire, noires, Nouar |
|
\@est |
es, ai, haie, hais, hait |
Les requêtes de texte ne sont, par défaut, pas sensibles à la casse. Une requête pour business donnera des résultats avec le mot business ou Business, par exemple. Pour rendre une requête de texte sensible à la casse, utilisez le signe égal = avant le terme recherché :
| Sensible à la casse |
Résultats de recherche |
|---|---|
|
|
Cette requête rendra les enregistrements qui contiennent Business mais pas business. |
|
|
Cette requête combine une recherche sensible à la casse et une recherche par expression et renverra Business system mais pas business system. |
Comme les requêtes de texte sont insensibles à la casse par défaut, il est rarement nécessaire de préciser qu’elle ne l’est pas. Une situation dans laquelle cela serait utile est celle où nous spécifions une requête de phrase sensible à la casse mais où nous voulons qu'un mot de la phrase ne soit pas sensible à la casse. Nous utilisons \& pour spécifier l'insensibilité à la casse :
| Insensible à la casse |
Résultats de recherche |
|---|---|
|
\=\"This is about our Business \&Systems\" |
Cette requête permettrait de trouver à la fois This is about our Business Systems et This is about our Business systems. |
La correspondance de la casse et des diacritiques est spécifiée comme suit : \==.
| Requête | Trouver |
|---|---|
|
|
Cette requête rendra les enregistrements avec Sacré et Cœur exactement comme spécifié, c'est-à-dire en respectant la casse et les diacritiques, mais pas nécessairement l'un à côté de l'autre. |
|
|
Cet exemple combine une requête de phrases avec une correspondance de la casse et des diacritiques. Il retournera les enregistrements avec Sacré Cœur exactement comme spécifié, dans le même ordre et en respectant la casse et les diacritiques. |
Avec le filtrage, il est possible de :
- Substituer un ou plusieurs caractères génériques à une ou plusieurs lettres dans un terme de recherche.
- Spécifier qu'un terme apparaît au début ou à la fin d'un champ.
Conseil : Les caractères génériques peuvent être utilisés seuls, en combinaison les uns avec les autres et avec d'autres types de requêtes. Voir ci-dessous quelques exemples de requêtes combinées.
| Caractère générique |
Utilisation |
Exemples |
|---|---|---|
|
|
Substitue zéro ou plus caractères à sa position dans le terme de recherche. Conseil : Pour obtenir tous les enregistrements contenant quelque chose dans le champ de requête, c'est-à-dire tous les champs non vides, entrez |
appl\* correspondra aux mots commençant par appl, par exemple apple, application, applied, etc. edit\* correspondra aux mots commençant par edit, par exemple edit, edits, edited, etc. |
|
|
Substitue n'importe quel caractère unique à sa position dans le terme de recherche. |
appl\? correspondra à apply et apple (mais pas à apples). par\?e correspondrait à parle, parme et parte. \?\?\? correspondra à toute combinaison de trois graphèmes (lettres, chiffres, tout caractère). |
|
|
Placé au début d'un terme de recherche, il indique que le terme doit apparaître au début du champ. |
\^Hôpital correspondrait à Hôpital pour Grands Brûlés, et Hôpital Militaire (mais pas Grand Hôpital ou Nouvel Hôpital). \^the correspondra aux enregistrements dont le texte commence par le mot the. |
|
|
Placé à la fin d'un terme de recherche, il indique que le terme doit apparaître à la fin du champ. |
Organisation\$ correspondrait à Comité d'Organisation (mais pas à Organisation des Médecins Légistes). ?\$ correspondra aux enregistrements dont le texte se termine par un point d'interrogation. |
|
|
Correspond à l'un des caractères d'une séquence spécifiée dans l'un des éléments de. l'un des éléments de peut consister en des caractères individuels, ou l'on peut spécifier un caractère de début et de fin d'une plage séparés par un signe moins (par exemple, |
Organi\[sz\]ation correspondra à Organisation et Organization. \[0-9\] correspondra à tout numéro compris entre 0 et 9. |
|
|
Correspond à un ou plusieurs caractères d'une séquence de caractères spécifiée de un ou davantage de. un ou davantage de peut consister en des caractères individuels, ou l'on peut spécifier un caractère de début et de fin d'une plage séparés par un signe moins (par exemple, |
Organi\{sz\}ation correspondra à Organisation, Organization et (en cas de faute de frappe) Organiszation. |
Quelques requêtes utiles avec des caractères génériques
|
Caractère générique |
Description |
Exemple |
|---|---|---|
|
|
Ceci retournera que les enregistrements qui ont le seul mot terme dans le champ de recherche, c'est-à-dire terme doit être le début et la fin de la valeur dans un champ. Note: |
|
|
|
Cela renverra les enregistrements ne contenant rien dans le champ de requête (un champ vide). Comme nous l'avons vu, \* est utile si vous souhaitez renvoyer tous les enregistrements contenant quelque chose (n'importe quoi) dans le champ de requête. \!\* signifie « rechercher ce champ avec RIEN dedans », en d'autres termes, vide. Note: Voir Recherche d'un champ vide : une requête NULL pour plus de détails. |
|
|
|
Ceci est utile quand vous n'êtes pas sûr de l'orthographe du terme de recherche. |
|
|
|
Utilisé dans un champ de fichiers joints, il indique tous les enregistrements n'ayant PAS de lien avec d'autres, n'étant joints à aucun autres. |
|
|
|
Utilisé dans un champ de fichiers joints, il indique tous les enregistrements qui sont reliés (joints) à un ou plusieurs autres. |
Lors d'une requête dans un champ numérique, de date ou d'heure et de latitude/longitude, il est possible de rechercher une plage de valeurs (par exemple, de 1 à 100, ou entre le 1er janvier 1994 et le 1er janvier 2005). Les opérateurs relationnels (>, >=, <, <=) sont utilisés pour spécifier la limite inférieure, supérieure, ou inférieure et supérieure de la date, de l'heure ou du nombre que vous recherchez.
Conseil : Les données alphanumériques sont traitées un peu différemment des données numériques (les champs de date peuvent contenir des données alphanumériques et les valeurs des champs de latitude et de longitude sont par nature alphanumériques, c'est-à-dire 51 39 00 N). Lorsque vous utilisez des données alphanumériques dans une requête par plage, la valeur doit être placée entre guillemets (par exemple,\"51 39 00 N\" ou \"1 janvier 1970\").
Conseil : Il n'est pas nécessaire d'utiliser les symboles d'échappement avec les opérateurs relationnels (>,>=,<,<=).
Conseil : Il n'est pas nécessaire d'utiliser le signe égal (=) pour trouver une date ou un nombre spécifique.
Conseil : Il est possible de préciser une limite inférieure ou supérieure en combinant les termes de recherche encadrée. Par exemple >=30 <=50 trouvera les enregistrements de 30 à 50 inclus.
|
Opérateur |
Description |
Exemple |
|---|---|---|
|
|
Trouve les enregistrements supérieurs à la date ou au nombre spécifié(e). |
>\"2 avril 1999\" trouvera les enregistrements postérieurs au 2 avril 1999. >890 trouvera les enregistrements supérieurs à 890. |
|
|
Trouve les enregistrements inférieurs à la date ou au nombre spécifié(e). |
<\"2 avril 1999\" trouvera les enregistrements antérieurs au 2 avril 1999. <890 trouvera les enregistrements inférieurs à 890. |
|
|
Trouve des enregistrements supérieurs ou égaux à la date ou au nombre spécifié(e). |
>=\"2 avril 1999\" trouvera les enregistrements postérieurs ou égaux au 2 avril 1999. >=890 trouvera les enregistrements supérieurs ou égaux à 890. Note: Pour les raisons expliquées dans Un avertissement sur les recherches encadrées partielles il est préférable d’éviter l’utilisation de > = dans une recherche encadrée partielle (c'est-à-dire avec une date incomplète ou latitude / longitude). |
|
|
Trouve les enregistrements inférieurs ou égaux à la date ou au nombre spécifié(e). |
<=\"2 avril 1999\" trouvera les enregistrements antérieurs ou égaux au 2 avril 1999. <=890 trouvera les enregistrements inférieurs ou égaux à 890. Note: Pour les raisons expliquées dans Un avertissement sur les recherches encadrées partielles il est préférable d’éviter l’utilisation de < = dans une recherche encadrée partielle (c'est-à-dire avec une date incomplète ou latitude / longitude). |
Lorsque vous effectuez une recherche encadrée partielle, il est important d'éviter d'utiliser = avec un opérateur relationnel (< ou >).
Considérez cette requête utilisant une date partielle :
AdmDateModified >= 2012
Il y a en fait deux requêtes ici :
- Localiser les enregistrements avec une date supérieure à 2012.
- Localiser les enregistrements qui égalent 2012.
La première recherche retournera tous les enregistrements où AdmDateModified est à partir du 1 janvier 2013, ce qui est conforme aux attentes.
Cependant, la deuxième partie ne retournera jamais de résultat. Une date enregistrée dans EMu comprend trois parties (jour/mois/année), mais certaines parties de la date dans notre terme de requête ne sont pas inconnues : dans ce cas, le jour et le mois sont techniquement NULL (bien qu'il puisse être plus facile de comprendre NULL comme UNKNOWN). L'objectif de notre requête est de retourner tout enregistrement dont l'année est 2012, mais lorsque nous utilisons le modificateur d'égalité (=), nous demandons en fait que la date enregistrée dans AdmDateModified corresponde exactement à NULL/NULL/2012 (ou UNKNOWN/UNKNOWN/2012). Cela ne correspondra bien sûr à rien.
Une méthode fiable pour capturer tous les enregistrements d'une année où le jour et/ou le mois peuvent être manquants consiste simplement à effectuer une requête par année. Par exemple, pour trouver tous les enregistrements créés en 2019 ou après, vous pouvez effectuer une requête :
AdmDateModified >2018
Cela renverra tous les enregistrements à partir du 1er janvier 2019.
Latitude / Longitude
Un problème similaire se pose avec des valeurs de latitude et longitude DMS partielles.
Considérer cette requête utilisant une latitude partielle :
LatLatitude_nesttab >=\"34 30 S\"
Il y a en fait deux requêtes ici :
- Localiser les enregistrements où la latitude est supérieure à 34 30 S.
- Localiser les enregistrements où la latitude est égale à 34 30 S.
La première recherche retournera tous les enregistrements avec une latitude nord de 34 30 S.
Cependant, la deuxième partie ne retournera jamais de résultat. Comme avec les dates, la raison est que vous ne pouvez pas avoir une latitude partielle ÉGALE à quelque chose puisque certaines parties de la latitude DMS sont inconnues (dans ce cas secondes est NULL).
Encore une fois, la solution est d'éviter d'utiliser <= et >= avec des plages partielles. La requête :
LatLatitude_nesttab >\"34 31 S\"
retournera les enregistrements avec une latitude égale à ou au nord de 34 30 S.
La requête de Proximité permet de rechercher des mots dans un champ de texte et de préciser le nombre de mots, de phrases ou de paragraphes qui les séparent. La requête de Proximité repose sur le principe selon lequel la proximité de deux termes suggère qu'ils sont associés l'un à l'autre. Cela peut s'avérer utile lors de la requête de champs contenant de grandes quantités de texte.
Les recherches de proximité ont la forme suivante :
\'(terme1 terme2\) modificateur opérateur nombre unité\'
où :
|
terme1 terme2 |
sont les deux termes à rechercher et son entre parenthèses, par ex :
\(département hôpital\) |
|
ordre |
est optionnel. S’ils sont donnés, les termes de requête doivent être dans l'ordre spécifié. |
|
modificateur |
est soit :
-OU-
|
|
opérateur |
est un opérateur relationnel (<, <=, >, >=, =). Note: Les opérateurs relationnels n'ont pas besoin d'être échappés dans une requête. |
|
nombre |
est un nombre ou une plage pour indiquer la proximité ou la plage de proximité de chaque terme par rapport à l'autre, par ex. |
|
unité |
est l'unité de proximité dans laquelle effectuer la recherche, par exemple : word (mot), sentence (phrase) ou paragraph (paragraphe)
\(state hospital\)<= 5 words trouvera les enregistrements pour lesquels les termes de requête state et hospital sont séparés par un nombre de mots égal ou inférieur à cinq. Note: L'unité de proximité peut être abrégée à la première lettre du mot, c'est-à-dire w pour |
L'expression de requête entière est placée entre guillemets simples, par exemple :
\'\(state hospital\) <= 5 w\'
Vous voulez trouver des documents Bibliographiques sur l'éthique du clonage. Vous tapez clon\* et ethic\* dans le champ Notes et vous lancez une requête. L'enregistrement suivant est l'une des correspondances :

Même si les deux termes apparaissent dans le même dossier, ils sont assez éloignés l'un de l'autre et, bien que le dossier traite du clonage et mentionne l'éthique, il ne porte pas sur l'éthique du clonage.
Pour affiner la requête, vous lancez maintenant une requête de proximité. Cette requête précise que deux termes doivent s'afficher à moins de cinq mots l'un de l'autre :
\'\(clon\* ethic\*\) <= 5 words\'
Cette fois, l'enregistrement ci-dessus n'est pas trouvé, car les termes de requête sont trop éloignés. Toutefois, cette requête permet de trouver l'enregistrement suivant, car les deux termes s'affichent à moins de cinq mots l'un de l'autre. La probabilité que cet enregistrement porte sur le thème de l'éthique et du clonage est beaucoup plus élevée, et c'est effectivement le cas :

Les différents types de requête peuvent être combinés de différentes manières efficaces. Par exemple :
| Trouver | Requête |
|---|---|
|
Enregistrements dont au moins un mot contient une majuscule |
\=\*S\*
|
|
Enregistrements où Fred apparaît de manière significative dans la même phrase que la phonétique de Smith où Fred apparaît en premier. |
|
|
Enregistre où le caractère kanji 豈 apparaît à moins de 5 caractères de l'expression 香 港. |
|
|
Les enregistrements qui contiennent autre chose que le seul mot Inconnu. |
\!\^Unknown\$
|
|
Les enregistrements qui ne contiennent pas la phrase Not Applicable. |
\!\"Not Applicable\"
|
|
Enregistrements contenant la phrase Sacré Cœur avec la signification des majuscules et des diacritique, mais pas si le champ recherché comprend également le mot Paris. |
\"\==Sacré \==Cœur\" \!Paris
|
|
Enregistrements contenant une majuscule ou une minuscule |
|
|
Enregistrements contenant du texte dont le premier mot commence par une lettre Latine minuscule. |
|

